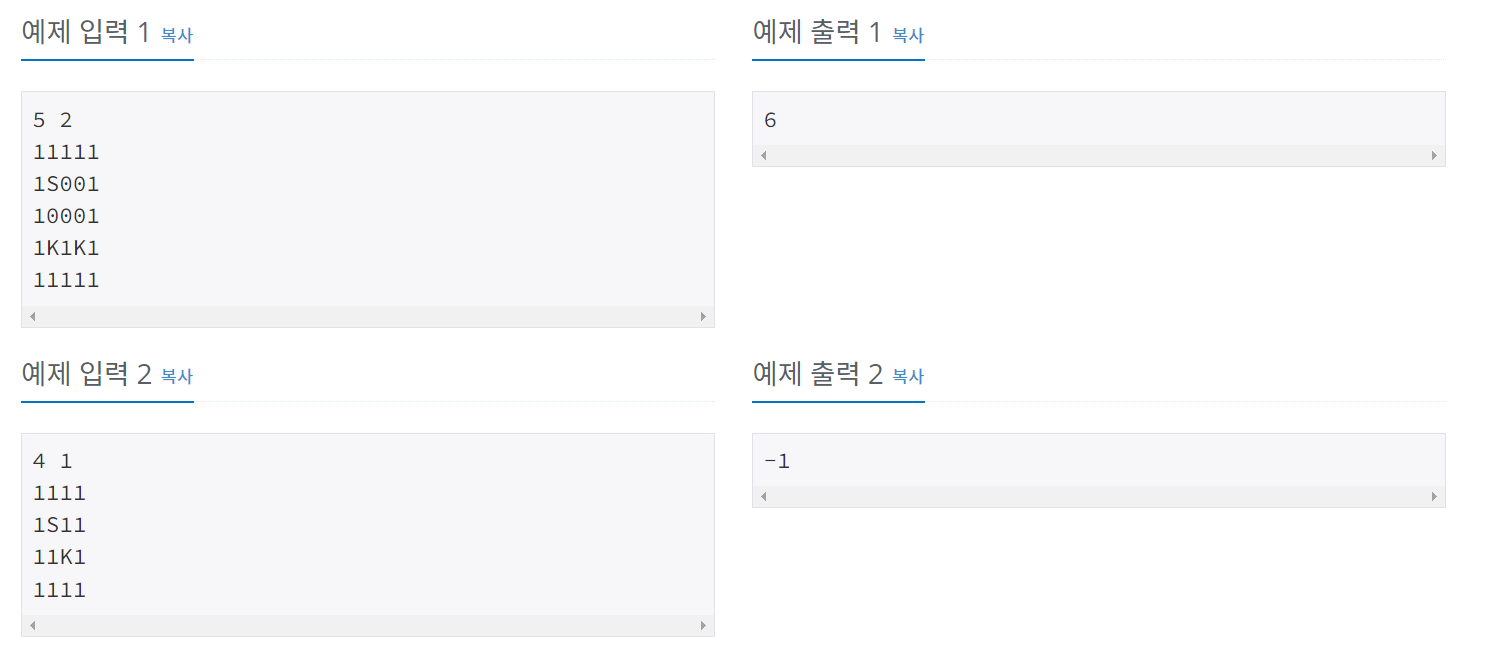
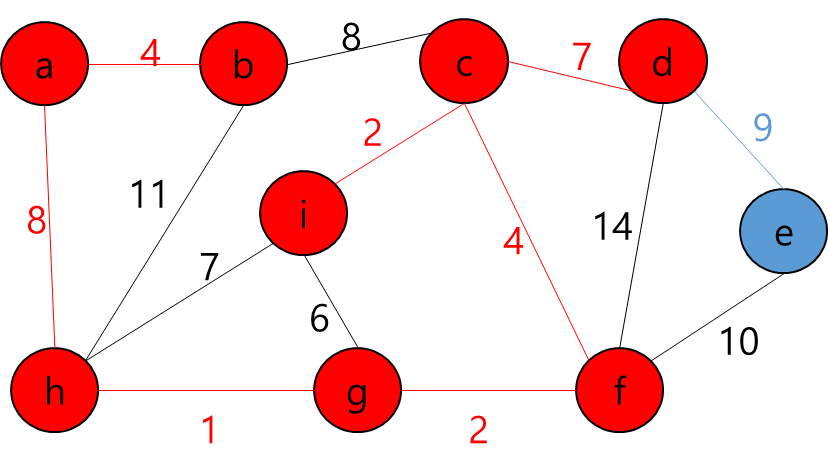
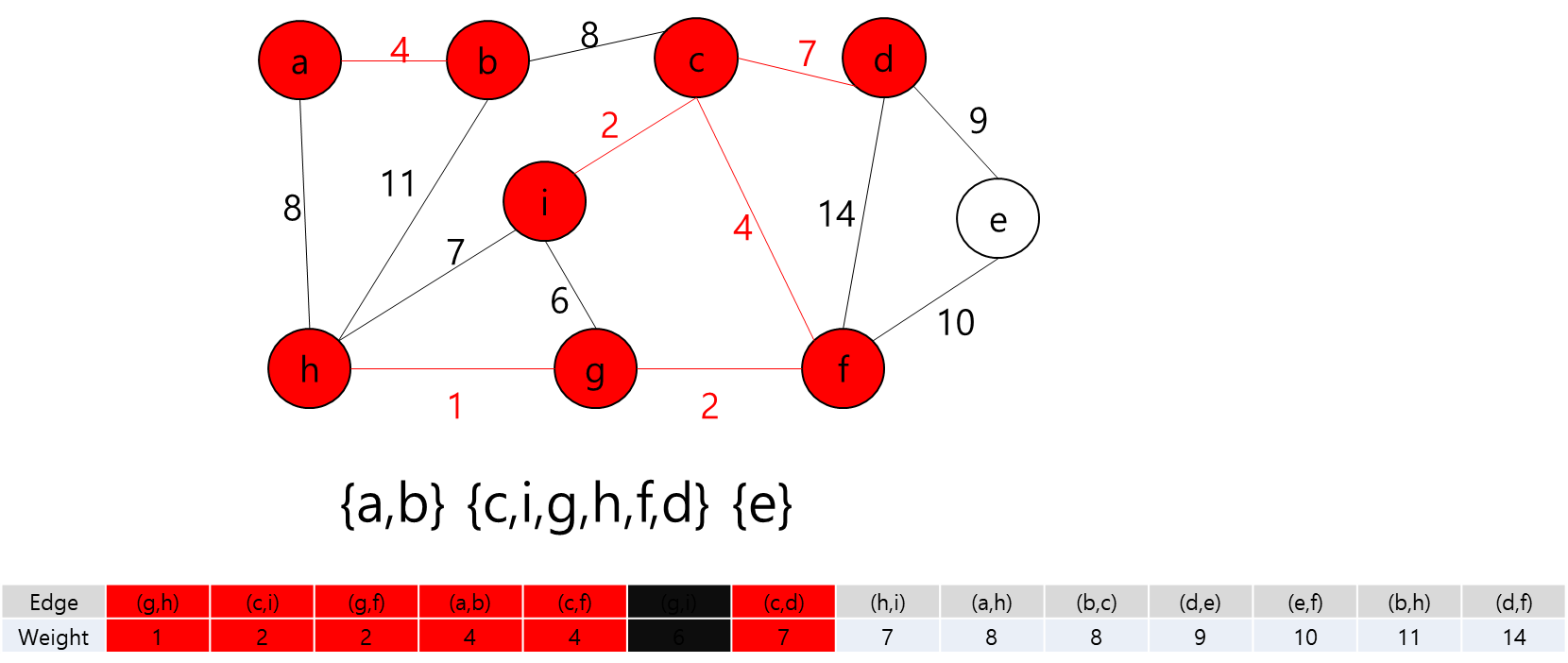
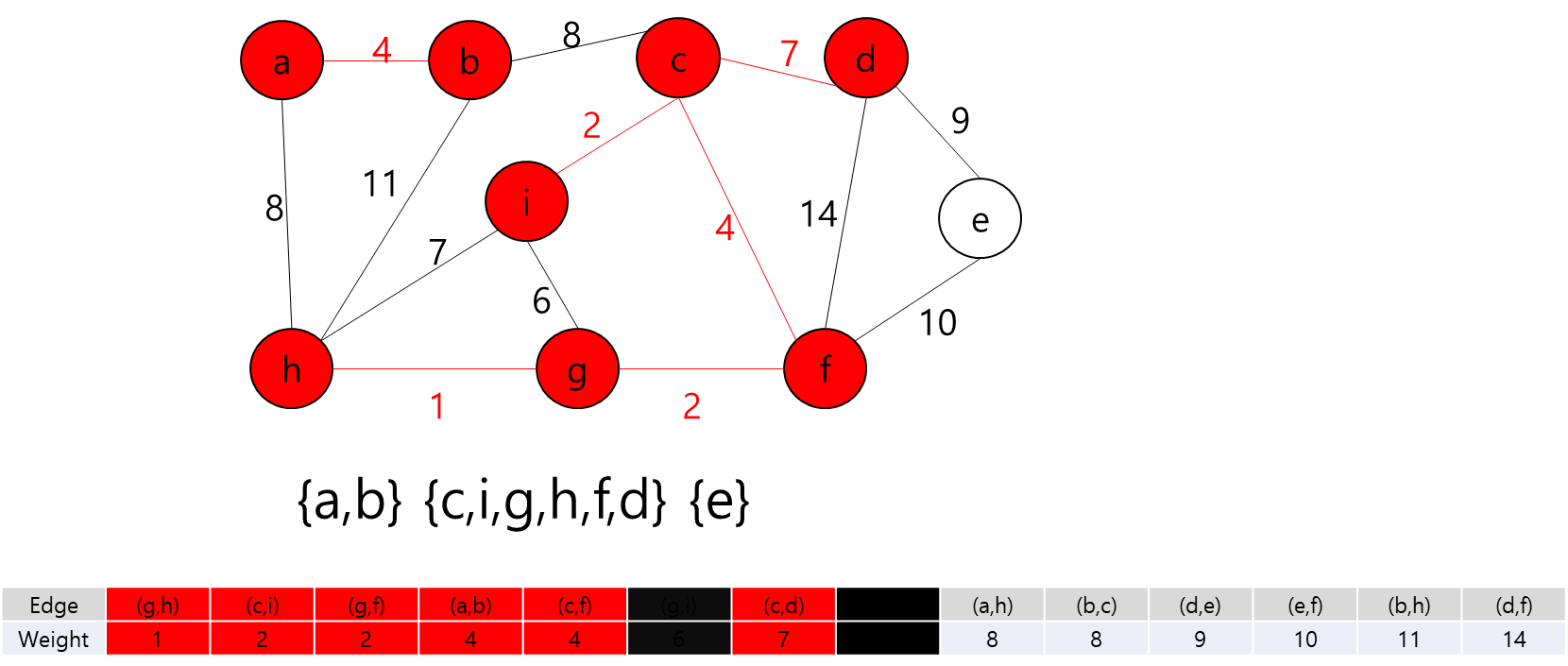
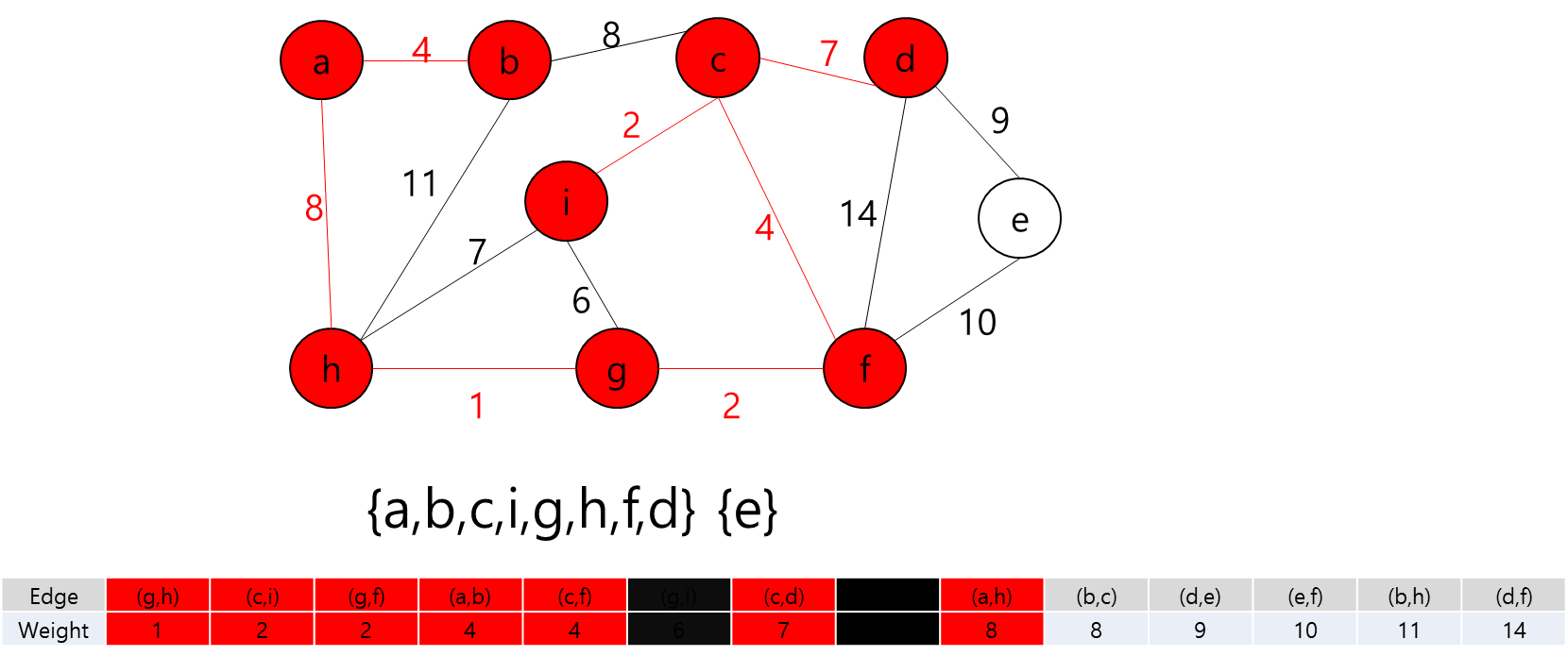
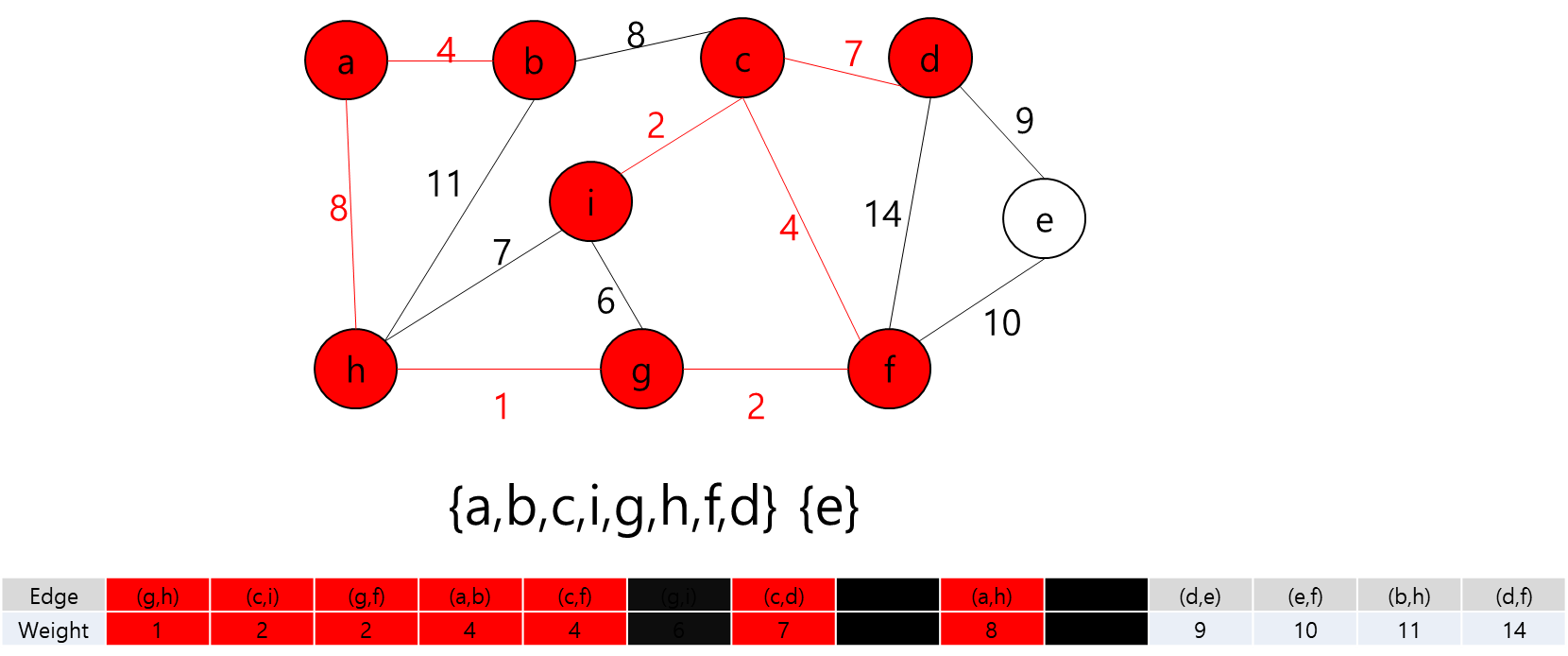
세준이는 어느 날 획기적인 로봇을 한 개 개발하였다. 그 로봇은 복제 장치를 이용하면 자기 자신을 똑같은 로봇으로 원하는 개수만큼 복제시킬 수 있다. 세준이는 어느 날 이 로봇을 테스트하기 위하여 어떤 미로에 이 로봇을 풀어 놓았다. 이 로봇의 임무는 미로에 흩어진 열쇠들을 모두 찾는 것이다. 그리고 열쇠가 있는 곳들과 로봇이 출발하는 위치에 로봇이 복제할 수 있는 장치를 장착해 두었다.
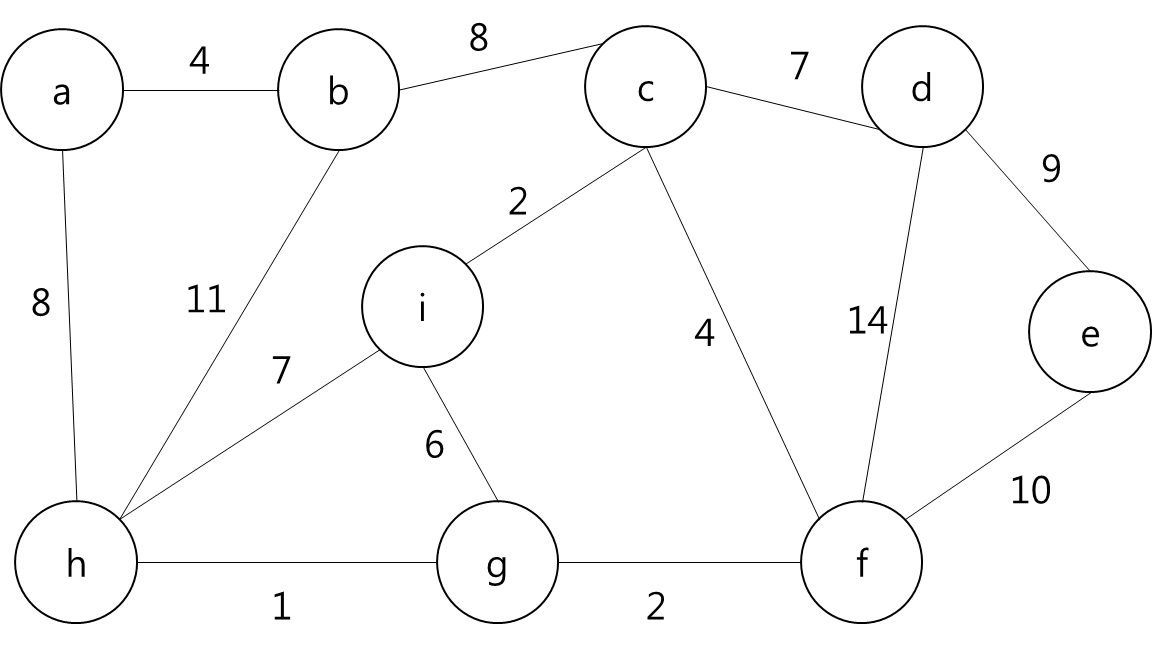
N*N의 정사각형 미로와 M개의 흩어진 열쇠의 위치, 그리고 이 로봇의 시작 위치가 주어져 있을 때, 모든 열쇠를 찾으면서 로봇이 움직이는 횟수의 합을 최소로 하는 프로그램을 작성하여라. 로봇은 상하좌우 네 방향으로 움직이며, 로봇이 열쇠가 있는 위치에 도달했을 때 열쇠를 찾은 것으로 한다. (복제된 로봇이어도 상관없다) 하나의 칸에 동시에 여러 개의 로봇이 위치할 수 있으며, 로봇이 한 번 지나간 자리라도 다른 로봇 또는 자기 자신이 다시 지나갈 수 있다. 복제에는 시간이 들지 않으며, 로봇이 움직이는 횟수의 합은 분열된 로봇 각각이 움직인 횟수의 총 합을 말한다. 복제된 로봇이 열쇠를 모두 찾은 후 같은 위치로 모일 필요는 없다.
입력
첫째 줄에 미로의 크기 N(4 ≤ N ≤ 50)과 열쇠의 개수 M(1 ≤ M ≤ 250) 이 공백을 사이에 두고 주어진다. 그리고 둘째 줄부터 N+1째 줄까지 미로의 정보가 주어진다. 미로는 1과 0, 그리고 S와 K로 주어진다. 1은 미로의 벽을 의미하고, 0은 지나다닐 수 있는 길, S는 로봇이 출발하는 위치, K는 열쇠의 위치가 주어진다. S는 1개, K는 M개가 주어진다. S와 K에서만 복제를 할 수 있음에 유의한다. 미로는 벽으로 둘러쌓여 있는 형태이다. 즉, 모든 테두리는 벽이다.
출력
첫째 줄에 모든 로봇이 움직인 횟수의 총 합을 출력한다. 모든 열쇠를 찾는 것이 불가능한 경우 횟수 대신 첫째 줄에 -1을 출력하면 된다.
2. 어떻게 풀까
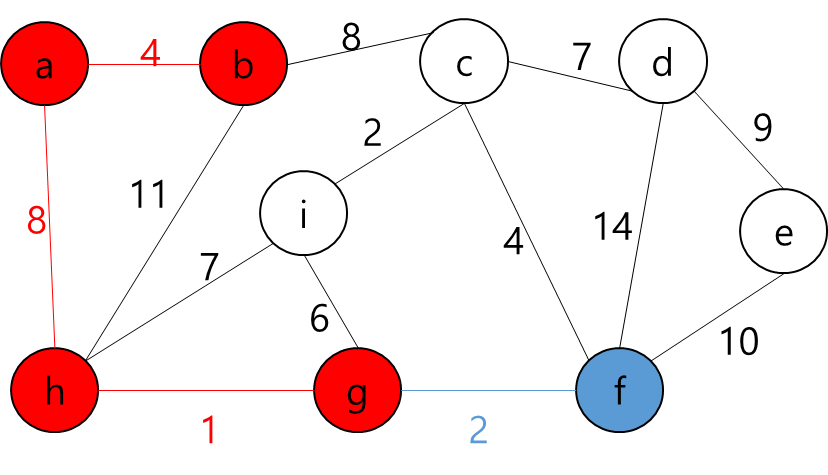
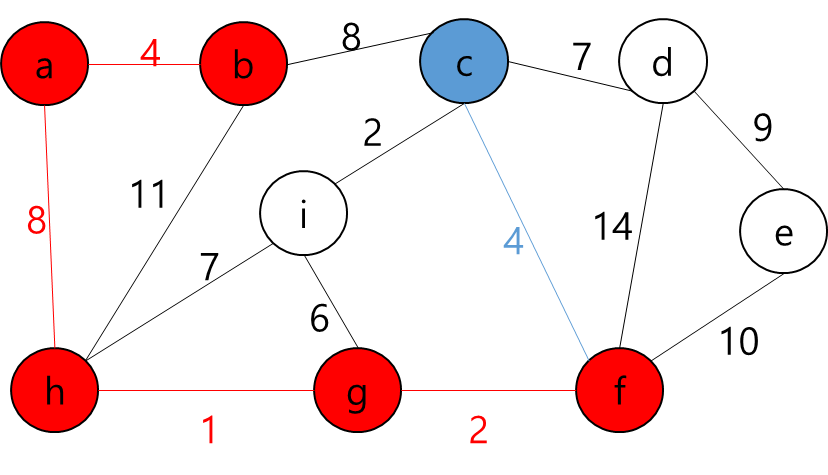
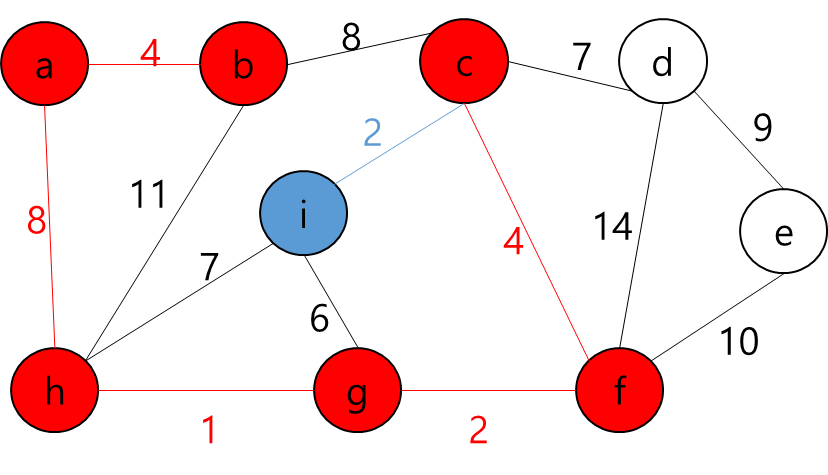
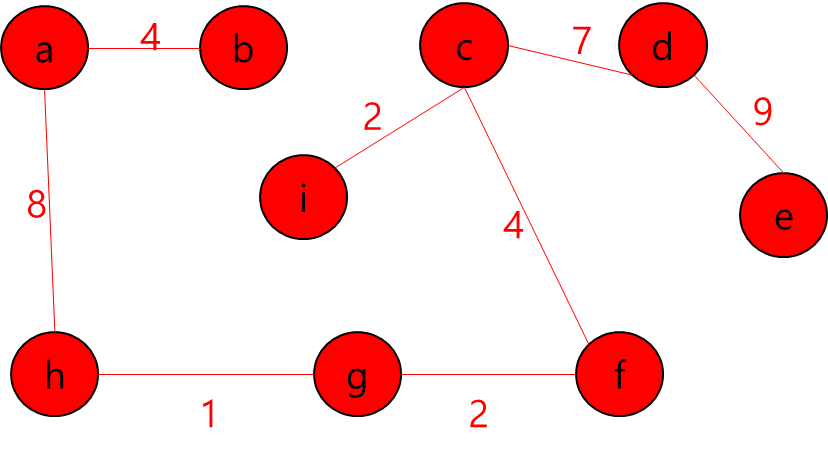
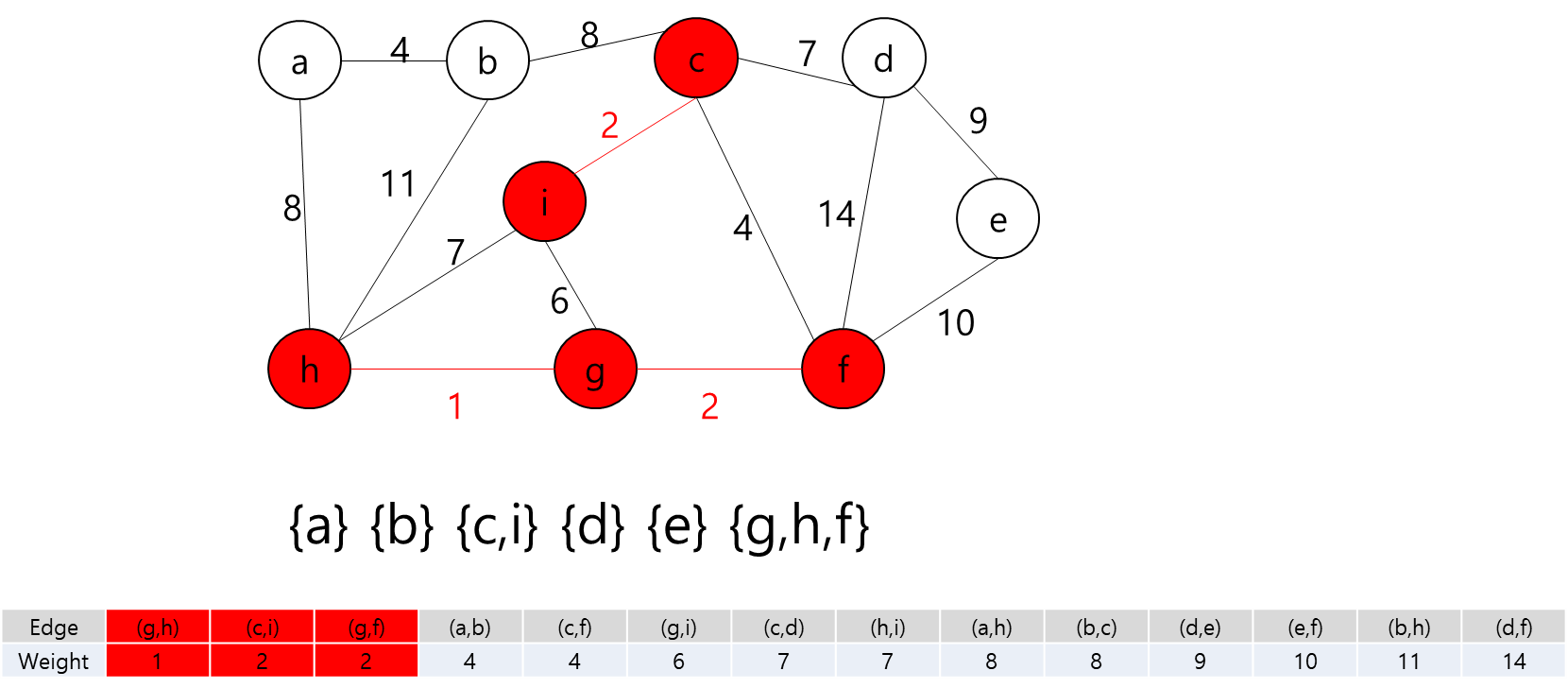
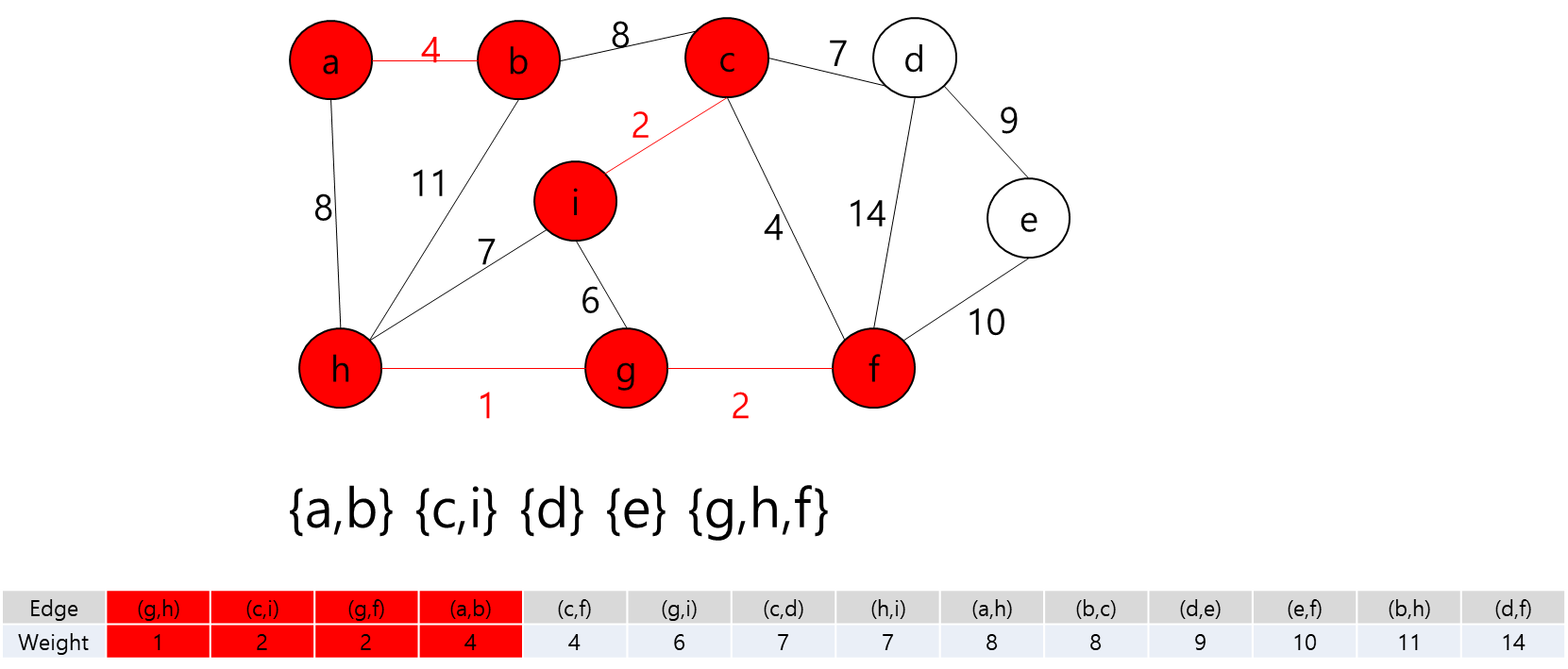
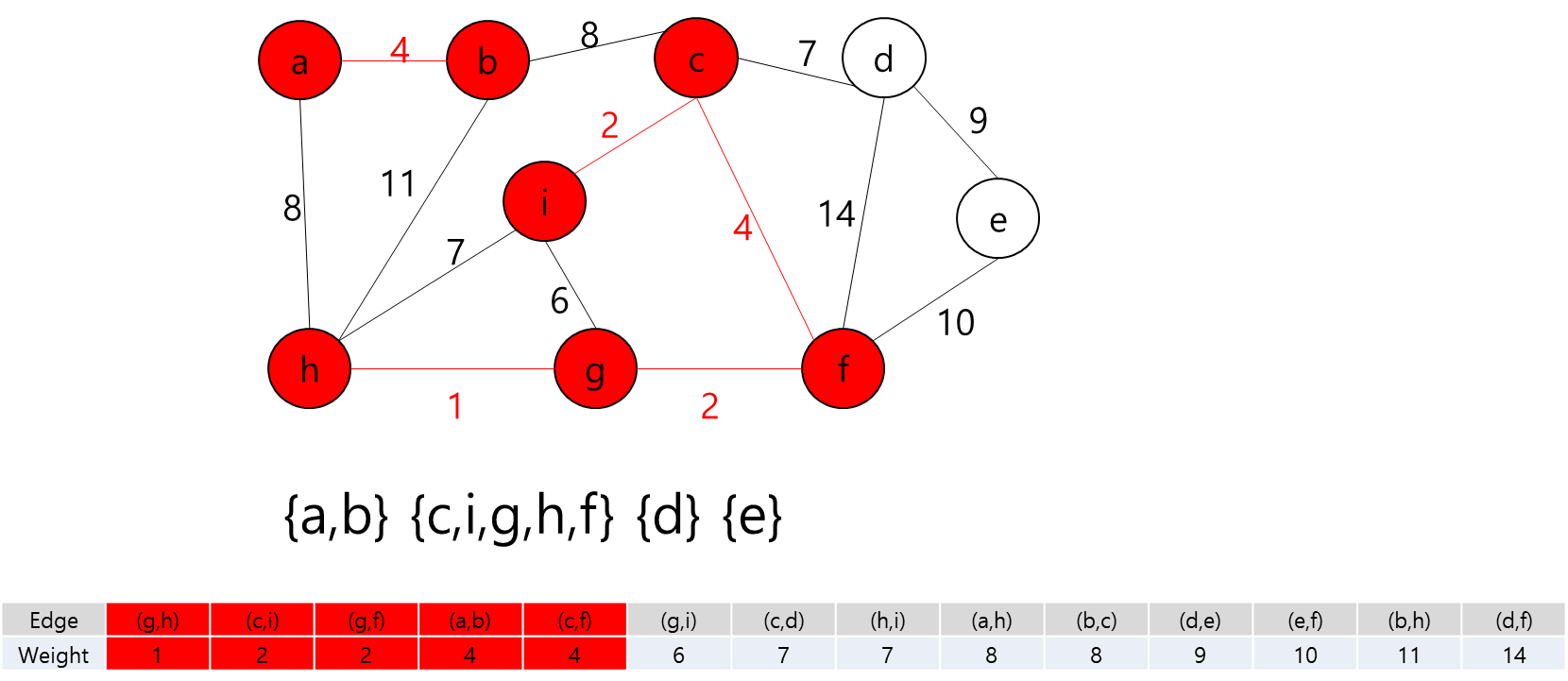
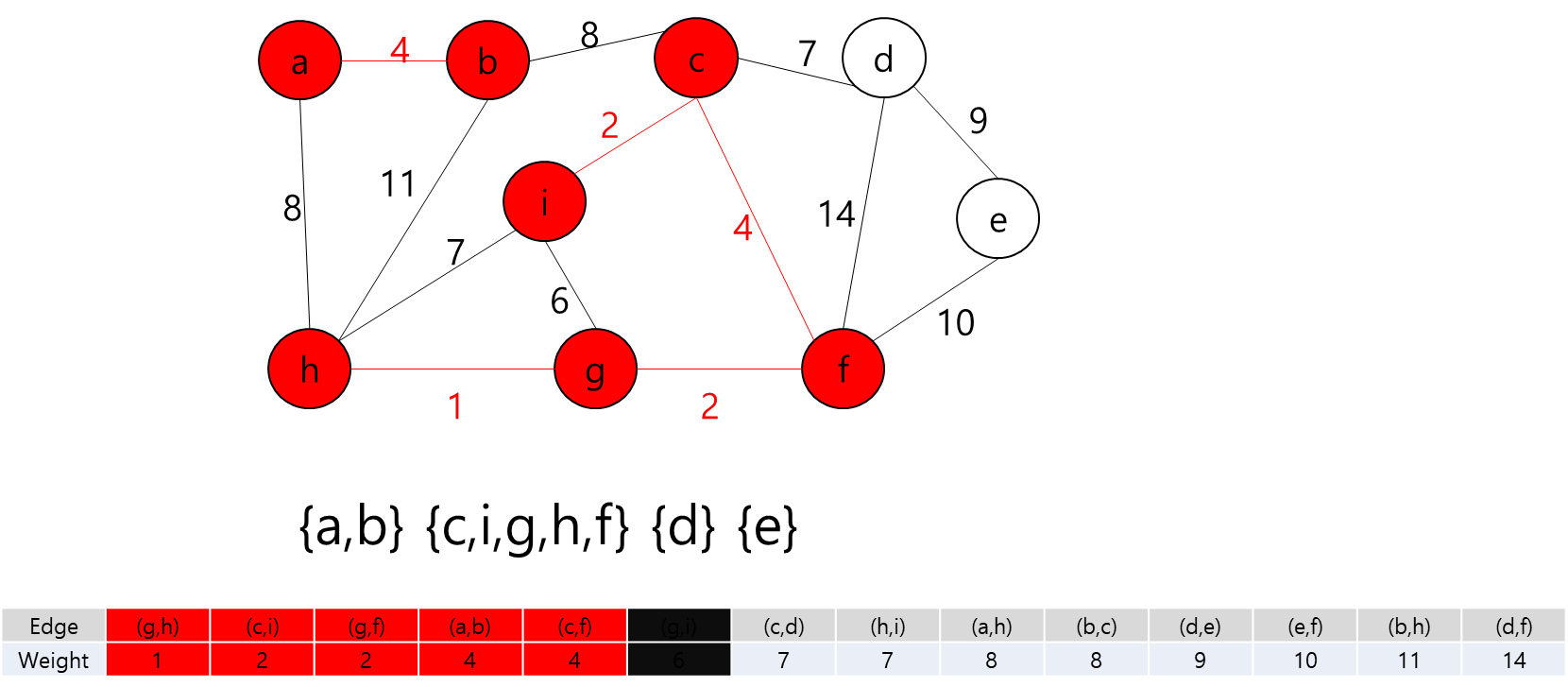
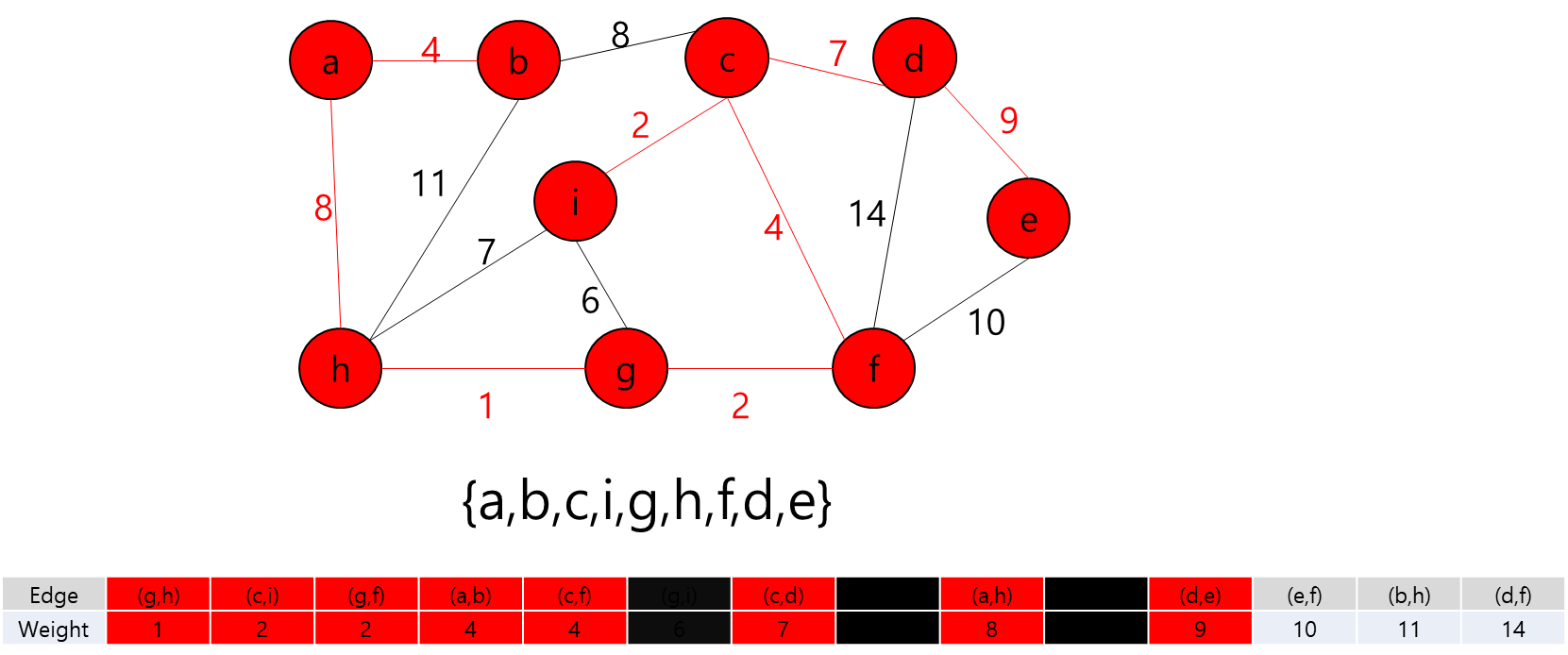
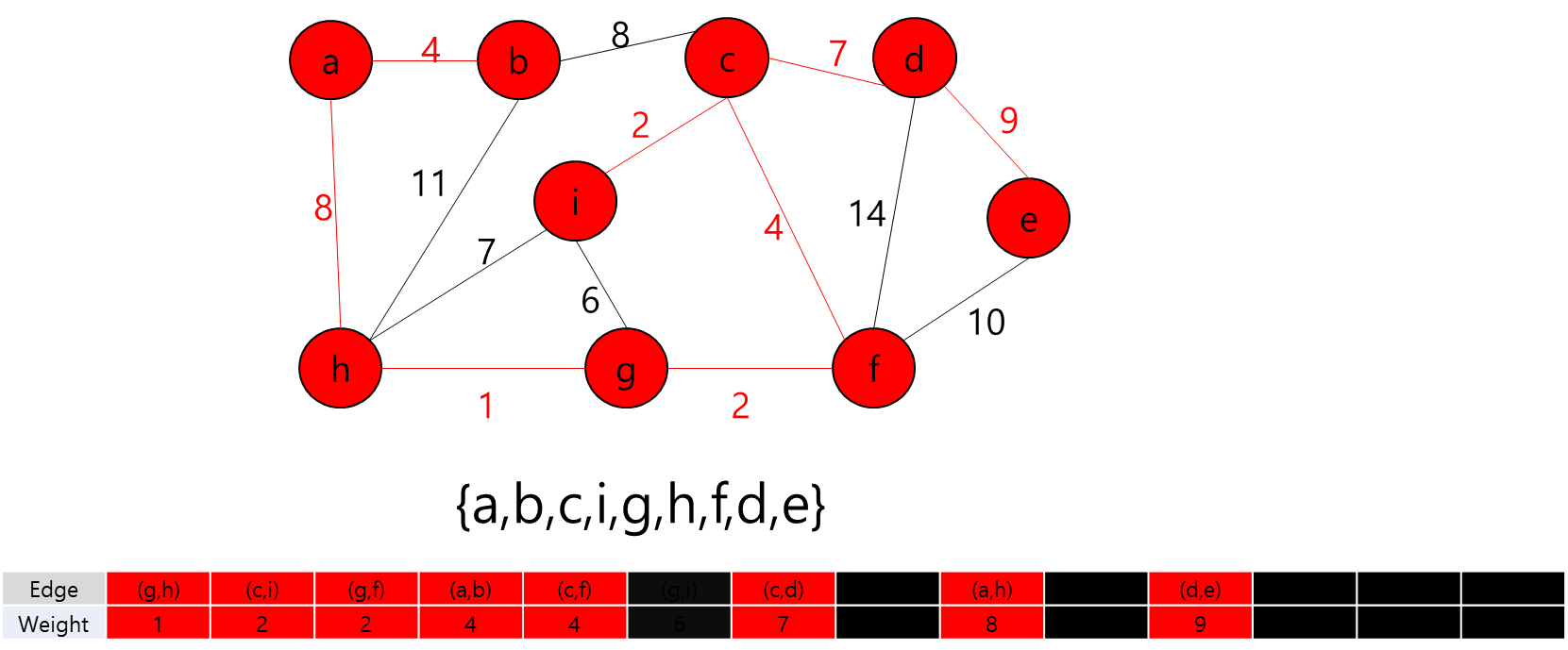
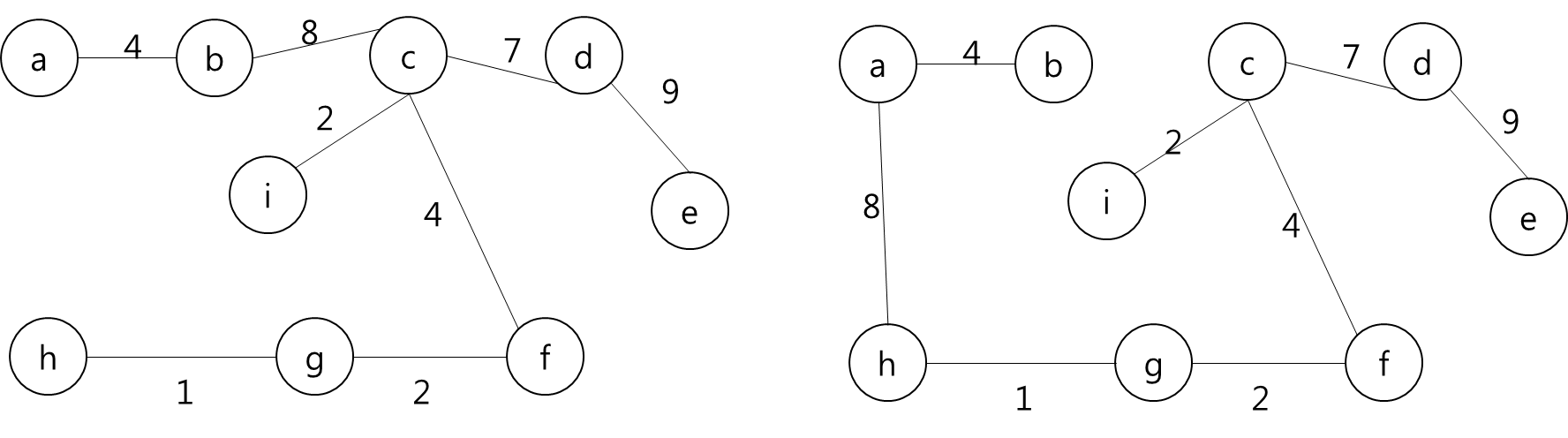
각 Key와 Start 지점에서 로봇이 복제 될 수 있다는 것은 A지점에서 출발해서 B지점으로 가는 거리가 Start 지점에서 B지점으로 가는 거리가 더 가까울 수 있다는 뜻이다.
그렇다는 것은..? 각 지점을 정점이라고 가정하고 각 정점끼리 간선이 이어져 있고 이 간선들을 이용해서 최소 신장 트리를 만들라는 얘기가 될 것이다.
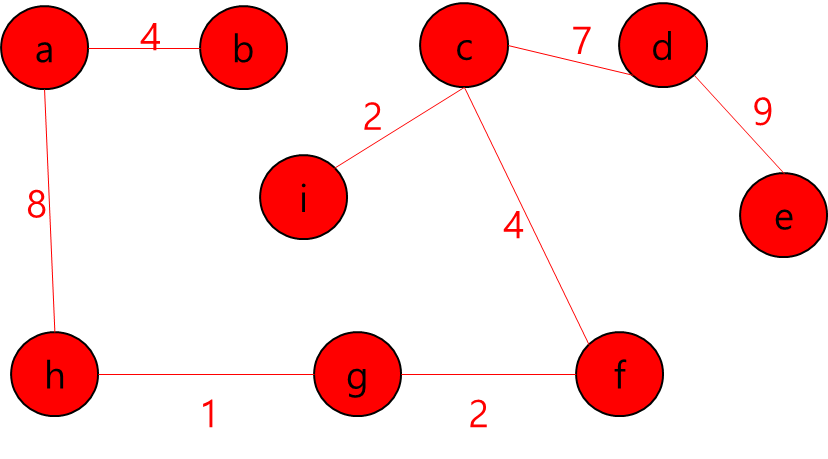
최소 신장 트리를 만들 수 없는 경우에는 -1을 출력하면 될 것이고, 최소 신장 트리가 만들어질 경우에는 그 가중치의 최솟값을 출력하면 되겠다.
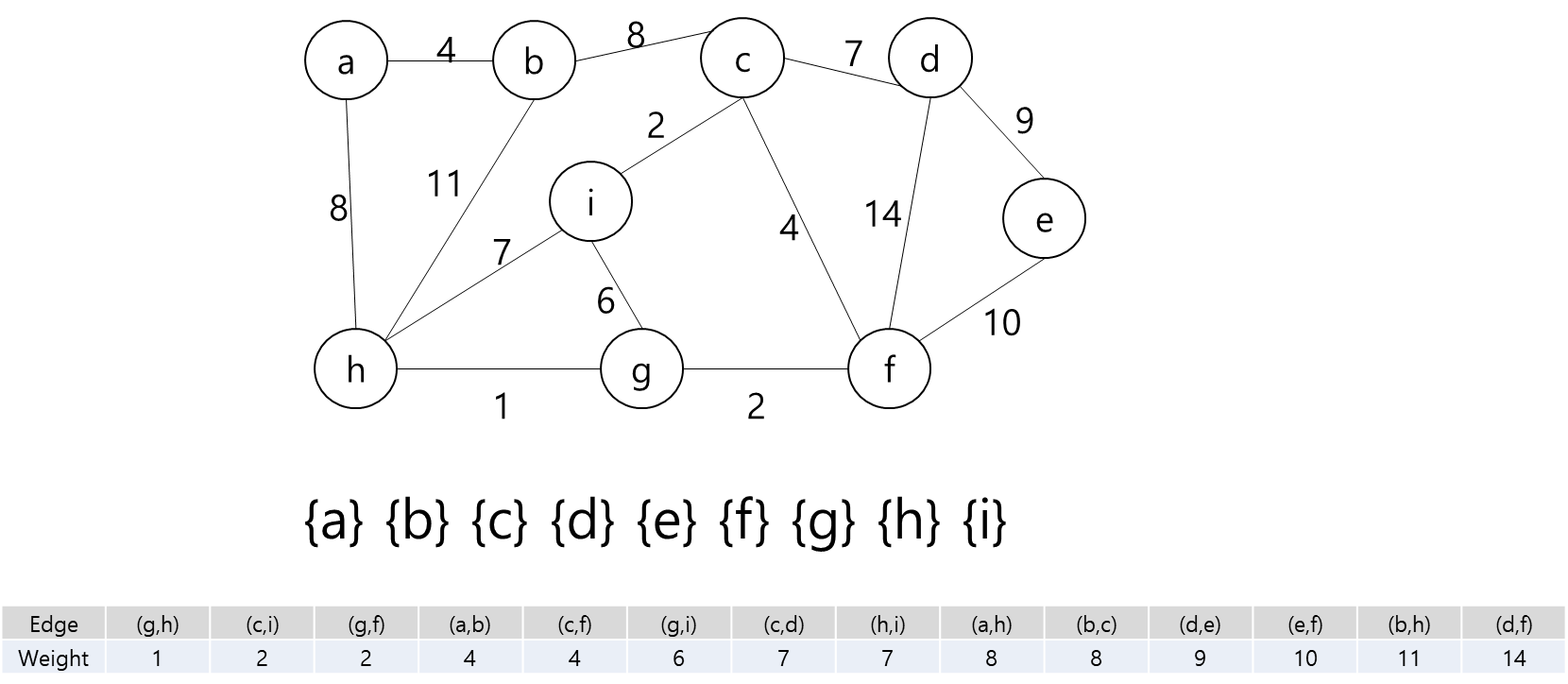
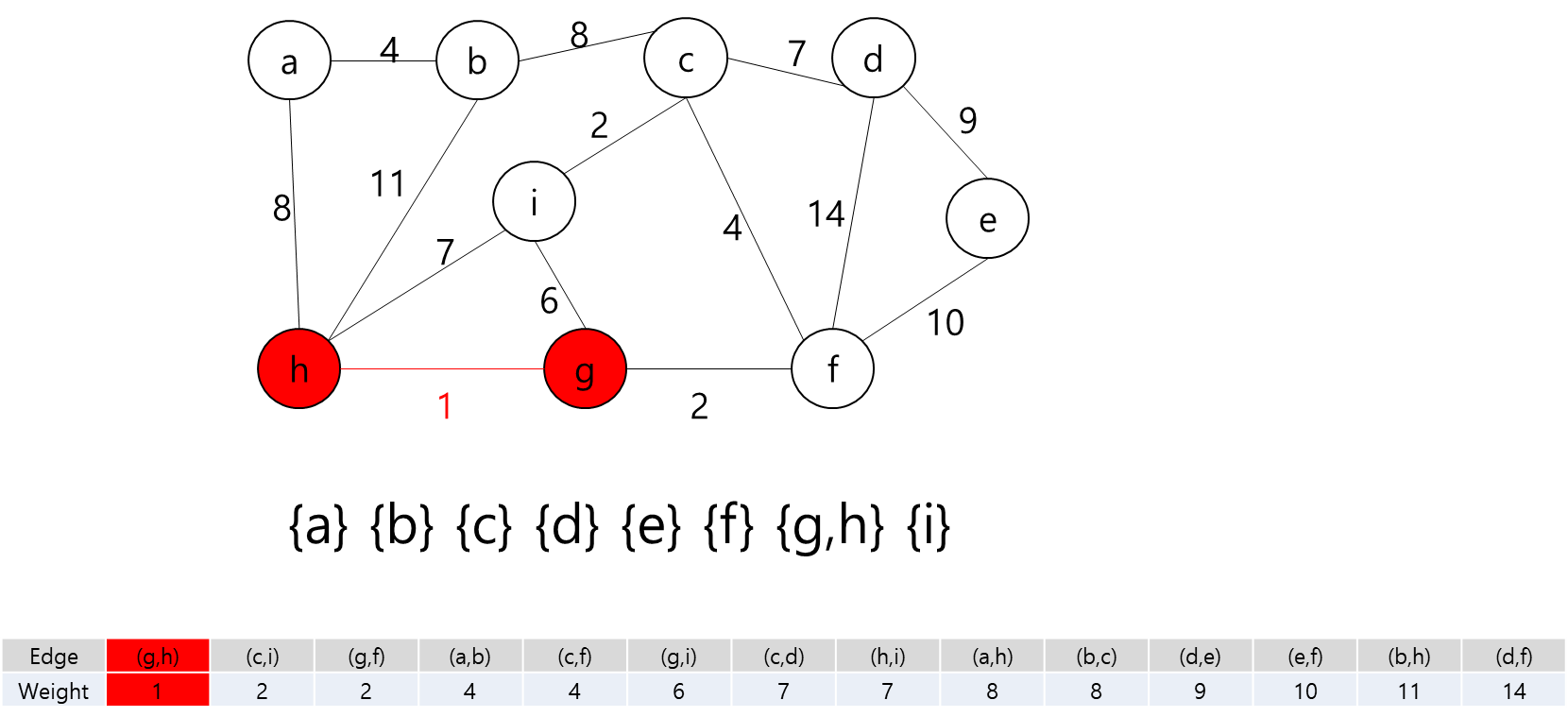
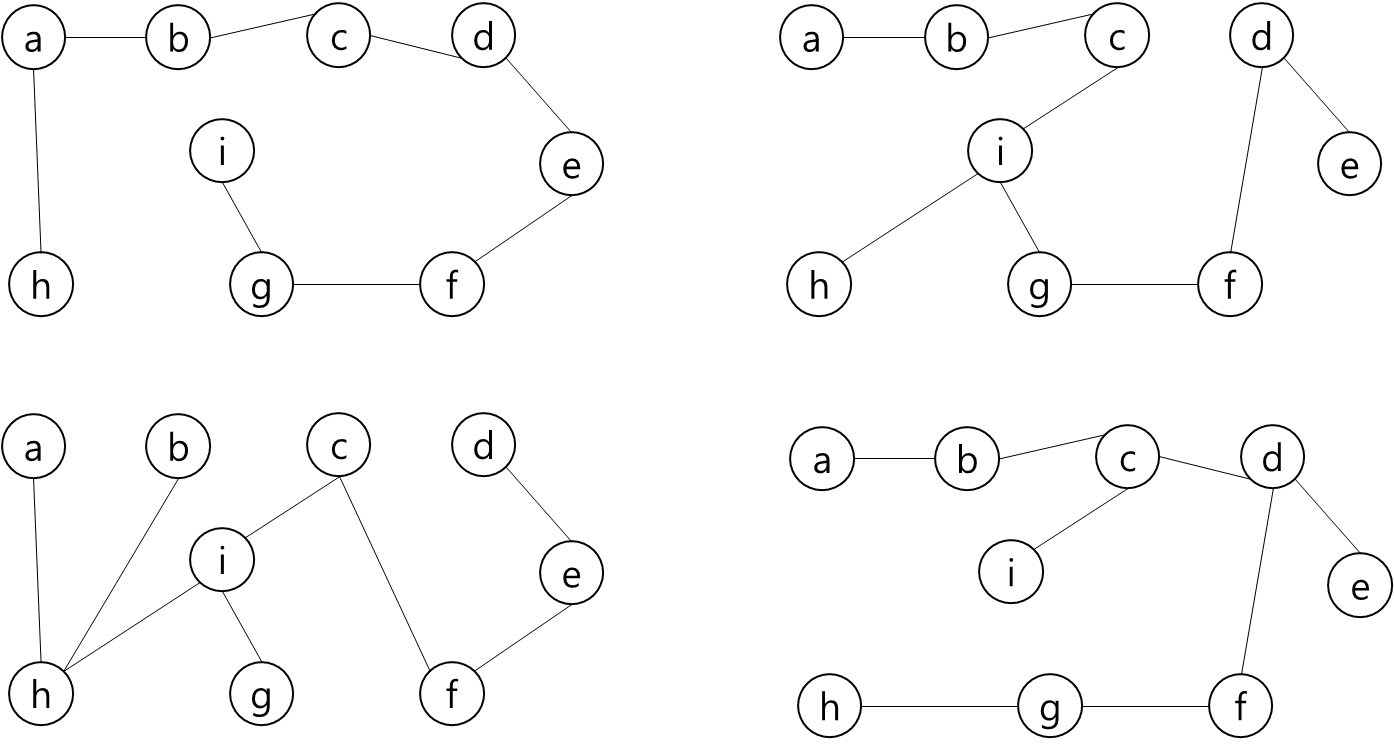
그렇다면 정점은 입력으로 주어진 map의 좌표를 이용해서 저장하면 될 것이고... 각 정점간의 간선을 어떻게 만들것인가.. map에서 상하좌우로만 움직일 수 있고, 각 좌표간 거리는 1이라고 했으니까 BFS를 이용해서 각 정점간의 거리를 구하고 그것을 이용해서 간선을 구현하면 되겠다.
드가보자
3. 코드 (자바, 통과한 코드)
package baekjoon.mst.복제로봇_20220120;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
publicclassMain{
privatestatic BufferedReader reader;
privatestaticint[] pointY = {0, 0, 1, -1};
privatestaticint[] pointX = {1, -1, 0, 0};
privatestatic List<int[]> edges;
privatestatic Vertex[] vertices;
privatestaticint[] parents;
publicstaticvoidmain(String[] args)throws IOException {
reader = new BufferedReader(new InputStreamReader(System.in));
edges = new ArrayList<>();
String[] parts = reader.readLine().split(" ");
int mapSize = Integer.parseInt(parts[0]);
int vertexCount = Integer.parseInt(parts[1]) + 1;
vertices = new Vertex[vertexCount];
char[][] maps = buildMapsAndAddVertex(mapSize);
for (Vertex vertex : vertices) {
getEdgesUsingBFS(maps, vertex);
}
parents = makeSet();
int result = kruskal();
System.out.println(isMST() ? result : -1);
}
privatestaticchar[][] buildMapsAndAddVertex(int mapSize) throws IOException {
char[][] maps = newchar[mapSize][mapSize];
int vertexIndex = 0;
for (int i = 0; i < mapSize; i++) {
String line = reader.readLine();
for (int j = 0; j < mapSize; j++) {
maps[i][j] = line.charAt(j);
if (isSourceOrKey(maps[i][j])) {
vertices[vertexIndex] = new Vertex(i, j, vertexIndex++);
}
}
}
return maps;
}
privatestaticbooleanisSourceOrKey(char c){
return c == 'S' || c == 'K';
}
privatestaticvoidgetEdgesUsingBFS(char[][] maps, Vertex sourceVertex){
Queue<int[]> queue = new LinkedList<>();
boolean[][] visit = newboolean[maps.length][maps.length];
visit[sourceVertex.y][sourceVertex.x] = true;
queue.add(newint[]{sourceVertex.y, sourceVertex.x, 0});
while (!queue.isEmpty()) {
int[] current = queue.poll();
int currentY = current[0];
int currentX = current[1];
int distanceFromSourceVertex = current[2];
for (int i = 0; i < 4; i++) {
int nextY = currentY + pointY[i];
int nextX = currentX + pointX[i];
if (!visit[nextY][nextX] && isValidPoint(maps, nextY, nextX)) {
visit[nextY][nextX] = true;
queue.add(newint[]{nextY, nextX, distanceFromSourceVertex + 1});
if (isSourceOrKey(maps[nextY][nextX])) {
for (Vertex destinationVertex : vertices) {
if (destinationVertex.y == nextY && destinationVertex.x == nextX) {
edges.add(newint[]{sourceVertex.id, destinationVertex.id, distanceFromSourceVertex + 1});
break;
}
}
}
}
}
}
}
privatestaticbooleanisValidPoint(char[][] maps, int nextY, int nextX){
return (nextY >= 0 && nextY < maps.length)
&& (nextX >= 0 && nextX < maps.length)
&& (maps[nextY][nextX] != '1');
}
privatestaticintkruskal(){
edges.sort(Comparator.comparingInt(x -> x[2]));
int result = 0;
for (int[] edge : edges) {
int from = edge[0];
int to = edge[1];
int weight = edge[2];
if (find(parents, from) != find(parents, to)) {
union(parents, from, to);
result += weight;
}
}
return result;
}
privatestaticint[] makeSet() {
int[] parents = newint[vertices.length];
for (int i = 0; i < parents.length; i++) {
parents[i] = i;
}
return parents;
}
privatestaticintfind(int[] parents, int x){
if (parents[x] == x) {
return x;
}
return parents[x] = find(parents, parents[x]);
}
privatestaticvoidunion(int[] parents, int x, int y){
x = find(parents, x);
y = find(parents, y);
if (x == y) {
return;
}
if (x < y) {
parents[y] = x;
} else {
parents[x] = y;
}
}
privatestaticbooleanisMST(){
for (int i = 0; i < vertices.length; i++) {
if (find(parents, i) != 0) {
returnfalse;
}
}
returntrue;
}
privatestaticclassVertex{
int y;
int x;
int id;
publicVertex(int y, int x, int id){
this.y = y;
this.x = x;
this.id = id;
}
}
}
부가 설명 없이 코드만 보고 이해할 수 있는 코드...라고 믿고 부가 설명은 달지 않는다. (이해가 안되신다면 댓글 감사하겠습니다..)
근데 틀렸었다.
무수한 틀렸습니다...
틀린 이유를 코드를 보면서 골똘히 생각해봤는데 두 부분에서 버그가 있었다.
if (isSourceOrKey(maps[nextY][nextX])) {
for (Vertex destinationVertex : vertices) {
int destinationVertexId = -1;
if (destinationVertex.y == nextY && destinationVertex.x == nextX) {
destinationVertexId = destinationVertex.id;
break;
}
edges.add(
newint[]{sourceVertex.id, destinationVertex.id, distanceFromSourceVertex + 1});
}
}
BFS를 이용해서 각 Vertex간의 거리를 구하고 탐색하는 좌표가 Vertex에 해당하면 Edge를 만들어 저장하는 부분이다. 여기서 edges.add() 부분이 if (destinationVertex.y == nextY && destinationVertex.x == nextX) 안에 있어야 했다. 그렇지 않으면 index가 -1인 상태로 edges에 추가되어서 버그가 발생할 수 있다.
parents = makeSet();
int result = kruskal();
System.out.println(!edges.isEmpty() ? result : -1);
모든 Key에 닿을 수 있는 경우 가중치의 최솟값을 출력하고 그렇지 않은 경우 -1을 리턴하는 부분이다. 여기서 edges가 비어있는 경우를 모든 Key에 닿을 수 없는 경우로 생각하고 작성했는데, 생각해보니 edges 있어도 모든 Key에 닿을 수 있는 경우가 있을 수 있다. 그래서 find() 메소드로 모든 vertex들이 같은 집합인지 체크하는 isMST() 메소드를 작성하여 수정했다.
In this Kata, you will sort elements in an array by decreasing frequency of elements. If two elements have the same frequency, sort them by increasing value.
Solution.sortByFrequency(newint[]{2, 3, 5, 3, 7, 9, 5, 3, 7});
// Returns {3, 3, 3, 5, 5, 7, 7, 2, 9}// We sort by highest frequency to lowest frequency.// If two elements have same frequency, we sort by increasing value.
Map으로 (int, count) 데이터를 만들고, EntrySet list를 통해 value(count) 순으로 정렬 (count가 같다면 key 오름차순), 그리고 result list에 하나씩 담아 배열로 변환하여 리턴
근데 Best Practice를 보니까 Stream으로 신박하게 해결했다. 참고하면 좋을듯?
Collectors.groupingBy(), Function.identity(), Collectors.counting(), Comparator.<Integer, long>comparing() 메소드들은 처음 보는 메소드들인데 알아두면 Stream에서 요긴하게 쓸 수 있을듯
파이썬 코드
defsolve(arr):
int_count_map = {}
for integer in arr:
int_count_map.setdefault(integer, 0)
int_count_map[integer] = int_count_map.get(integer) + 1
sorted_by_value_dict = sorted(int_count_map.items(), key=lambda x: x[1], reverse=True)
result = []
for items in sorted_by_value_dict:
key = items[0]
value = items[1]
for i inrange(value):
result.append(key)
return result
defsolve_best_practice(arr):returnsorted(sorted(arr), key=lambda n: arr.count(n), reverse=True)
파이썬으로도 풀어보자 해서 억지로 풀긴했다. 근데 BestPractice보니까 헛웃음이 나더라