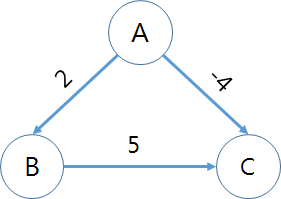
어느 날 이 N명의 학생이 X (1 ≤ X ≤ N)번 마을에 모여서 파티를 벌이기로 했다. 이 마을 사이에는 총 M개의 단방향 도로들이 있고 i번째 길을 지나는데 Ti(1 ≤ Ti ≤ 100)의 시간을 소비한다.
각각의 학생들은 파티에 참석하기 위해 걸어가서 다시 그들의 마을로 돌아와야 한다. 하지만 이 학생들은 워낙 게을러서 최단 시간에 오고 가기를 원한다.
이 도로들은 단방향이기 때문에 아마 그들이 오고 가는 길이 다를지도 모른다. N명의 학생들 중 오고 가는데 가장 많은 시간을 소비하는 학생은 누구일지 구하여라.
제한 사항
입력
첫째 줄에 N(1 ≤ N ≤ 1,000), M(1 ≤ M ≤ 10,000), X가 공백으로 구분되어 입력된다. 두 번째 줄부터 M+1번째 줄까지 i번째 도로의 시작점, 끝점, 그리고 이 도로를 지나는데 필요한 소요시간 Ti가 들어온다. 시작점과 끝점이 같은 도로는 없으며, 시작점과 한 도시 A에서 다른 도시 B로 가는 도로의 개수는 최대 1개이다.
모든 학생들은 집에서 X에 갈수 있고, X에서 집으로 돌아올 수 있는 데이터만 입력으로 주어진다.
출력
첫 번째 줄에 N명의 학생들 중 오고 가는데 가장 오래 걸리는 학생의 소요시간을 출력한다.
입출력 예
2. 어떻게 풀까?
처음 답
주어진 입력으로 인접리스트를 만든다.
Dijkstra 알고리즘을 이용하여 각 지점에서 X지점까지의 최단거리를 구한다.
Dijkstra 알고리즘을 이용하여 X지점에서 각 지점까지의 최단거리를 구한다.
가장 값이 큰 값을 출력한다.
다른 답 참고
인접리스트를 만들 때, from -> to의 정보를 to -> from 역방향 인접리스트를 하나 더 만든다.
각 지점에서 X지점까지 최단거리는 역방향 인접리스트에서 보면 X지점에서 각 지점까지의 최단거리와 같다.
그러므로
각 지점에서 X지점까지 최단거리는 역방향 인접리스트를 이용하고
X지점에서 각 지점까지는 인접리스트를 이용한다.
그 이후는 같다.
3. 코드
처음 답안 코드
import java.io.*;
import java.util.*;
classMain{
privatestaticfinal BufferedReader READER = new BufferedReader(new InputStreamReader(System.in));
privatestaticfinal BufferedWriter WRITER = new BufferedWriter(new OutputStreamWriter(System.out));
privatestatic StringTokenizer tokenizer;
privatestaticint vertexCount;
publicstaticvoidmain(String[] args)throws IOException {
tokenizer = new StringTokenizer(READER.readLine());
vertexCount = Integer.parseInt(tokenizer.nextToken());
int edgeCount = Integer.parseInt(tokenizer.nextToken());
int destination = Integer.parseInt(tokenizer.nextToken());
List<Edge>[] adjList = new List[vertexCount + 1];
for (int i = 1; i <= vertexCount; i++) {
adjList[i] = new ArrayList<>();
}
for (int i = 0; i < edgeCount; i++) {
tokenizer = new StringTokenizer(READER.readLine());
int from = Integer.parseInt(tokenizer.nextToken());
int to = Integer.parseInt(tokenizer.nextToken());
int weight = Integer.parseInt(tokenizer.nextToken());
adjList[from].add(new Edge(to, weight));
}
int max = Integer.MIN_VALUE;
for (int i = 1; i <= vertexCount; i++) {
int distance = dijkstra(adjList, i, destination) + dijkstra(adjList, destination, i);
max = Math.max(max, distance);
}
WRITER.write(max + "");
WRITER.flush();
WRITER.close();
READER.close();
}
privatestaticintdijkstra(List<Edge>[] adjList, int source, int destination){
PriorityQueue<Edge> queue = new PriorityQueue<>(Comparator.comparingInt(o -> o.weight));
int[] distance = newint[vertexCount + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
boolean[] visit = newboolean[vertexCount + 1];
queue.add(new Edge(source, 0));
distance[source] = 0;
while (!queue.isEmpty()) {
Edge currentEdge = queue.poll();
for (Edge adjEdge : adjList[currentEdge.to]) {
if (distance[adjEdge.to] > distance[currentEdge.to] + adjEdge.weight) {
distance[adjEdge.to] = distance[currentEdge.to] + adjEdge.weight;
queue.add(new Edge(adjEdge.to, distance[adjEdge.to]));
}
}
}
return distance[destination];
}
}
classEdge{
int to;
int weight;
publicEdge(int to, int weight){
this.to = to;
this.weight = weight;
}
}
다른 답 참고한 코드
import java.io.*;
import java.util.*;
classMain{
privatestaticfinal BufferedReader READER = new BufferedReader(new InputStreamReader(System.in));
privatestaticfinal BufferedWriter WRITER = new BufferedWriter(new OutputStreamWriter(System.out));
privatestatic StringTokenizer tokenizer;
privatestaticint vertexCount;
privatestaticint edgeCount;
publicstaticvoidmain(String[] args)throws IOException {
tokenizer = new StringTokenizer(READER.readLine());
vertexCount = Integer.parseInt(tokenizer.nextToken());
edgeCount = Integer.parseInt(tokenizer.nextToken());
int destination = Integer.parseInt(tokenizer.nextToken());
List<Edge>[] adjList = new List[vertexCount + 1];
List<Edge>[] reverseAdjList = new List[vertexCount + 1];
buildAdjList(adjList, reverseAdjList);
int max = Integer.MIN_VALUE;
int[] go_distance = dijkstra(reverseAdjList, destination);
int[] back_distance = dijkstra(adjList, destination);
for (int i = 1; i <= vertexCount; i++) {
max = Math.max(max, go_distance[i] + back_distance[i]);
}
WRITER.write(max + "");
WRITER.flush();
WRITER.close();
READER.close();
}
privatestaticvoidbuildAdjList(List<Edge>[] adjList, List<Edge>[] reverseAdjList)throws IOException {
for (int i = 1; i <= vertexCount; i++) {
adjList[i] = new ArrayList<>();
reverseAdjList[i] = new ArrayList<>();
}
for (int i = 0; i < edgeCount; i++) {
tokenizer = new StringTokenizer(READER.readLine());
int from = Integer.parseInt(tokenizer.nextToken());
int to = Integer.parseInt(tokenizer.nextToken());
int weight = Integer.parseInt(tokenizer.nextToken());
adjList[from].add(new Edge(to, weight));
reverseAdjList[to].add(new Edge(from, weight));
}
}
privatestaticint[] dijkstra(List<Edge>[] adjList, int source) {
PriorityQueue<Edge> queue = new PriorityQueue<>(Comparator.comparingInt(o -> o.weight));
int[] distance = newint[vertexCount + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
queue.add(new Edge(source, 0));
distance[source] = 0;
while (!queue.isEmpty()) {
Edge currentEdge = queue.poll();
for (Edge adjEdge : adjList[currentEdge.to]) {
if (distance[adjEdge.to] > distance[currentEdge.to] + adjEdge.weight) {
distance[adjEdge.to] = distance[currentEdge.to] + adjEdge.weight;
queue.add(new Edge(adjEdge.to, distance[adjEdge.to]));
}
}
}
return distance;
}
}
classEdge{
int to;
int weight;
publicEdge(int to, int weight){
this.to = to;
this.weight = weight;
}
}
4. 느낀 점
처음엔 Dijkstra 알고리즘만 알면 쉽게 풀 수 있는 문제라고 생각했는데 역방향 리스트를 만들어서 더 효율적으로 해결한 답을 보고 이런 방법도 있다는 것을 알 수 있었다. 알아 둬야겠다.
그러므로 N x개를 사용했을 때 표현 가능한 숫자는 - N을 x번 붙힌 값, (N 1개 표현 수) (덧셈, 뺄셈, 역뺄셈, 곱셈, 나눗셈, 역나눗셈) (N x-1개 표현수) U (N 2개 표현 수) (덧셈, 뺄셈, 역뺄셈, 곱셈, 나눗셈, 역나눗셈) (N x-2개 표현수) U ... U (N x/2개 표현 수) (덧셈, 뺄셈, 역뺄셈, 곱셈, 나눗셈, 역나눗셈) (N x/2개 표현수) 이다.
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Map;
publicclassSolution{
Map<Integer, HashSet<Integer>> calculationResultMap;
publicintsolution(int N, int number){
calculationResultMap = new HashMap<>();
for (int i = 1; i < 9; i++) {
HashSet<Integer> calculationResults = getCalculationValues(i, N);
if (calculationResults.contains(number)) {
return i;
}
calculationResultMap.put(i, calculationResults);
}
return -1;
}
private HashSet<Integer> getCalculationValues(int count, int N){
HashSet<Integer> set = new LinkedHashSet<>();
int attach = getAttachValue(count, N);
set.add(attach);
for (int j = 1; j <= count / 2; j++) {
for (int a : calculationResultMap.get(j)) {
for (int b : calculationResultMap.get(count - j)) {
for (Operator op : Operator.values()) {
set.add(op.calcuate(a, b));
}
}
}
}
return set;
}
privateintgetAttachValue(int count, int N){
return Integer.parseInt(Integer.toBinaryString((int) Math.pow(2, count) - 1)) * N;
}
}
enumOperator{
PLUS {
@Overridepublicintcalcuate(int a, int b){
return a + b;
}
},
MINUS {
@Overridepublicintcalcuate(int a, int b){
return a - b;
}
},
BACKMINUS {
@Overridepublicintcalcuate(int a, int b){
return b - a;
}
},
MULTIPLY {
@Overridepublicintcalcuate(int a, int b){
return a * b;
}
},
DIVIDE {
@Overridepublicintcalcuate(int a, int b){
return b == 0 ? 0 : a / b;
}
},
BACKDIVIDE {
@Overridepublicintcalcuate(int a, int b){
return a == 0 ? 0 : b / a;
}
};
abstractintcalcuate(int a, int b);
}
4. 느낀 점
처음 문제를 풀 때, N이 9개 이상이면 -1을 리턴하라고 해서 N 1개로 표현 가능한 식, 2개로 표현 가능한 식, ..., 8개로 표현 가능한 식을 Set에 담아서 그 식을 계산한 값이 number와 같으면 리턴하도록 코드를 작성하면 되겠구나 생각했다.
근데 처음 생각한 코드는, (N-N/N*NN+N) 같은 식은 괄호 위치에 따라 다르게 계산될 수 있는데 그걸 생각 못하고 앞에서부터 계산한 값만 생각했다. 그래서 계속 1번, 8번 테스트가 실패로 나왔다.
왜 틀렸는지 계속 생각해봐도 이해가 안 돼서 다른 사람들이 작성한 코드를 봤는데, 괄호 때문에 계산 순서가 달라질 수 있는 것을 고려하지 않은 점, 뺼셈과 나눗셈은 교환 법칙이 성립하지 않는 점을 생각하지 못해서 틀린 것 같다.
그 외에도 Enum을 사용해서 덧셈, 뺄셈, 역뺄셈, 곱셈, 나눗셈, 역나눗셈을 해결한 코드가 전혀 생각하지 못한 방법이라 똑같이 따라 해 보았다.
완전 탐색(DFS)을 이용하여 해결한 답도 많았는데, 해당 문제 카테고리가 DP(Dynamic Programming)이기도 했고, DFS를 이용하면 N*N-N/N 같은 식도 고려하지 않고 통과가 된다고 한다. 그래서 DFS는 따로 참고하지 않았다.
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리 초) 간 처리하는 요청의 최대 개수를 의미한다.
제한 사항
입력 형식
solution함수에 전달되는 lines배열은 N(1 ≦N≦ 2,000) 개의 로그 문자열로 되어 있으며, 각 로그 문자열마다 요청에 대한 응답 완료 시간 S와 처리시간 T가 공백으로 구분되어 있다.
응답 완료 시간 S는 작년 추석인 2016년 9월 15일만 포함하여 고정 길이 2016-09-15 hh:mm:ss.sss 형식으로 되어 있다.
처리시간 T는 0.1s,0.312s, 2s와 같이 최대 소수점 셋째 자리까지 기록하며 뒤에는 초 단위를 의미하는s로 끝난다.
예를 들어, 로그 문자열2016-09-15 03:10:33.020 0.011s은2016년 9월 15일 오전 3시 10분 **33.010초**부터2016년 9월 15일 오전 3시 10분 **33.020초**까지**0.011초**동안 처리된 요청을 의미한다.(처리시간은 시작시간과 끝시간을 포함)
서버에는 타임아웃이 3초로 적용되어 있기 때문에 처리시간은0.001 ≦ T ≦ 3.000이다.
설명: 처리시간은 시작시간과 끝시간을포함하므로 첫 번째 로그는01:00:02.003 ~ 01:00:04.002에서 2초 동안 처리되었으며, 두 번째 로그는01:00:05.001 ~ 01:00:07.000에서 2초 동안 처리된다. 따라서, 첫 번째 로그가 끝나는 시점과 두 번째 로그가 시작하는 시점의 구간인01:00:04.002 ~ 01:00:05.0011초 동안 최대 2개가 된다.
설명: 아래 타임라인 그림에서 빨간색으로 표시된 1초 각 구간의 처리량을 구해보면(1)은 4개,(2)는 7개,(3)는 2개임을 알 수 있다. 따라서초당 최대 처리량은 7이 되며, 동일한 최대 처리량을 갖는 1초 구간은 여러 개 존재할 수 있으므로 이 문제에서는 구간이 아닌 개수만 출력한다.
Write a function that accepts two square (NxN) matrices (two dimensional arrays), and returns the product of the two. Only square matrices will be given.
How to multiply two square matrices:
We are given two matrices, A and B, of size 2x2 (note: tests are not limited to 2x2). Matrix C, the solution, will be equal to the product of A and B. To fill in cell[0][0]of matrix C, you need to compute:A[0][0] * B[0][0] + A[0][1] * B[1][0].
More general: To fill in cell[n][m]of matrix C, you need to first multiply the elements in the nth row of matrix A by the elements in the mth column of matrix B, then take the sum of all those products. This will give you the value for cell[m][n]in matrix C.
입출력 예
a = {{1,2} {3,2}}
b = {{3,2},{1,1}}
result = {{5,4}{11,8}}
2. 어떻게 풀까?
n x n 행렬곱이기 때문에 결과도 n x n 행렬이 나온다. 직관적으로 일단 이중 for문이 필요하긴 할 것.


 vs
vs