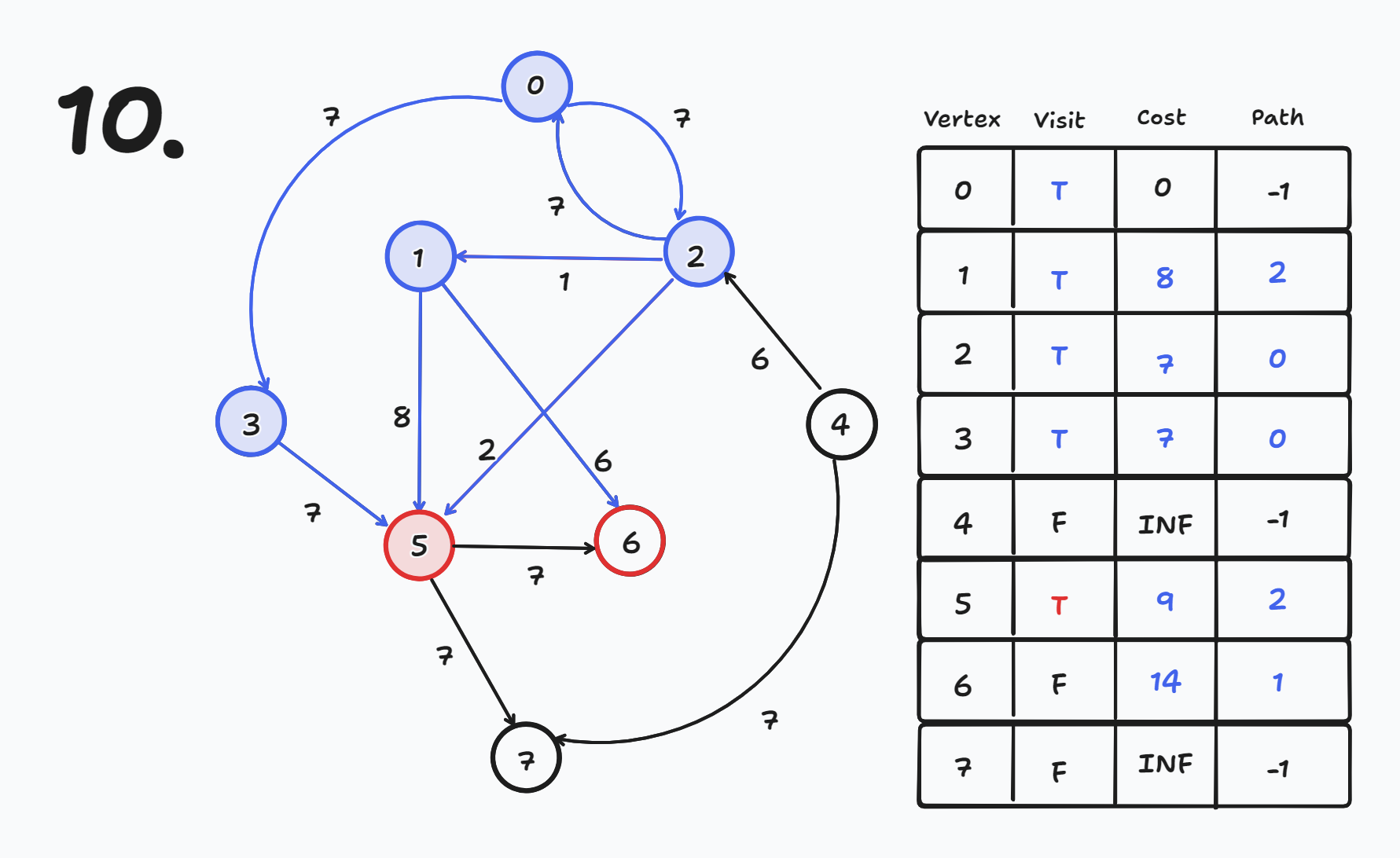
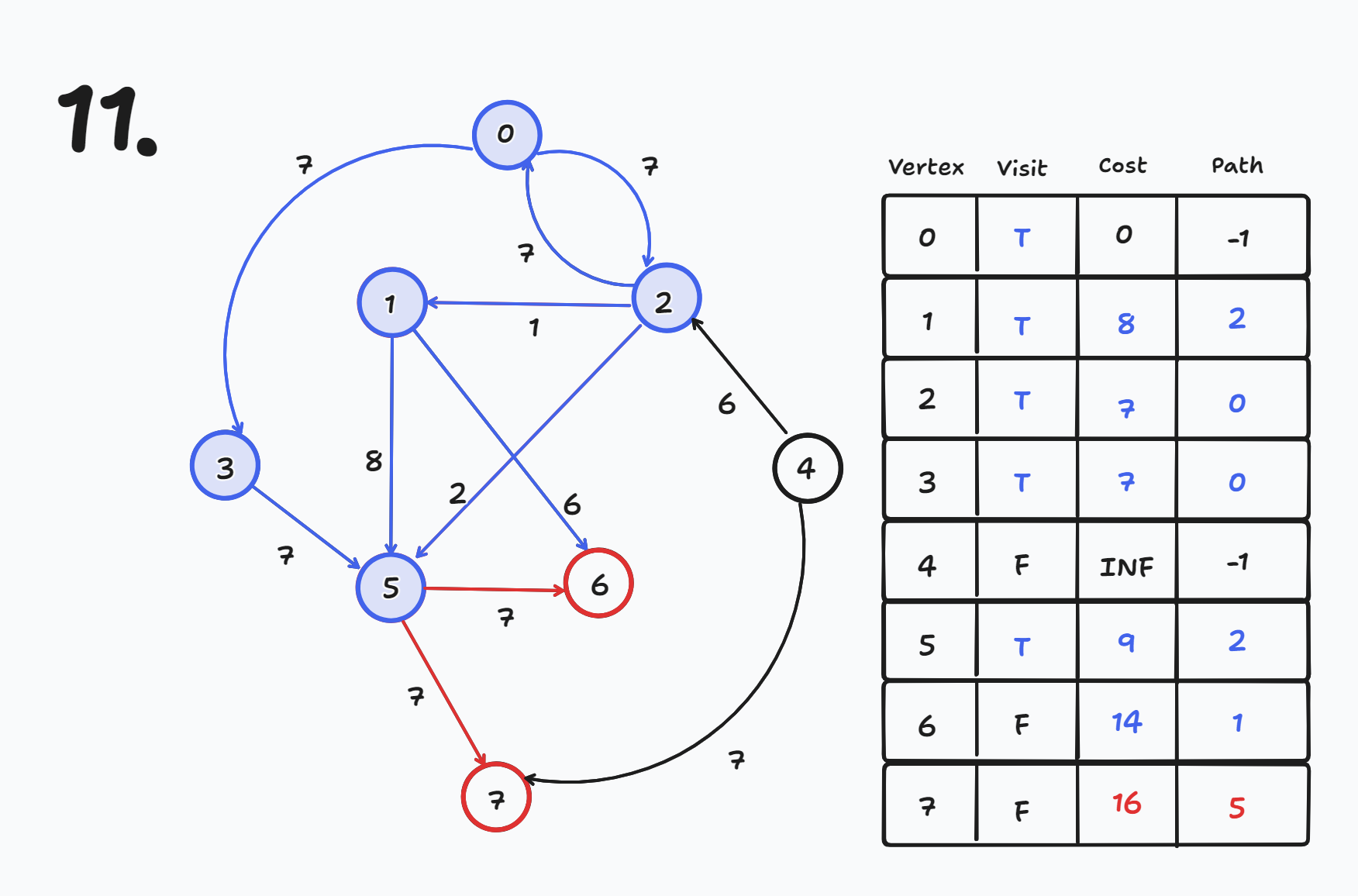
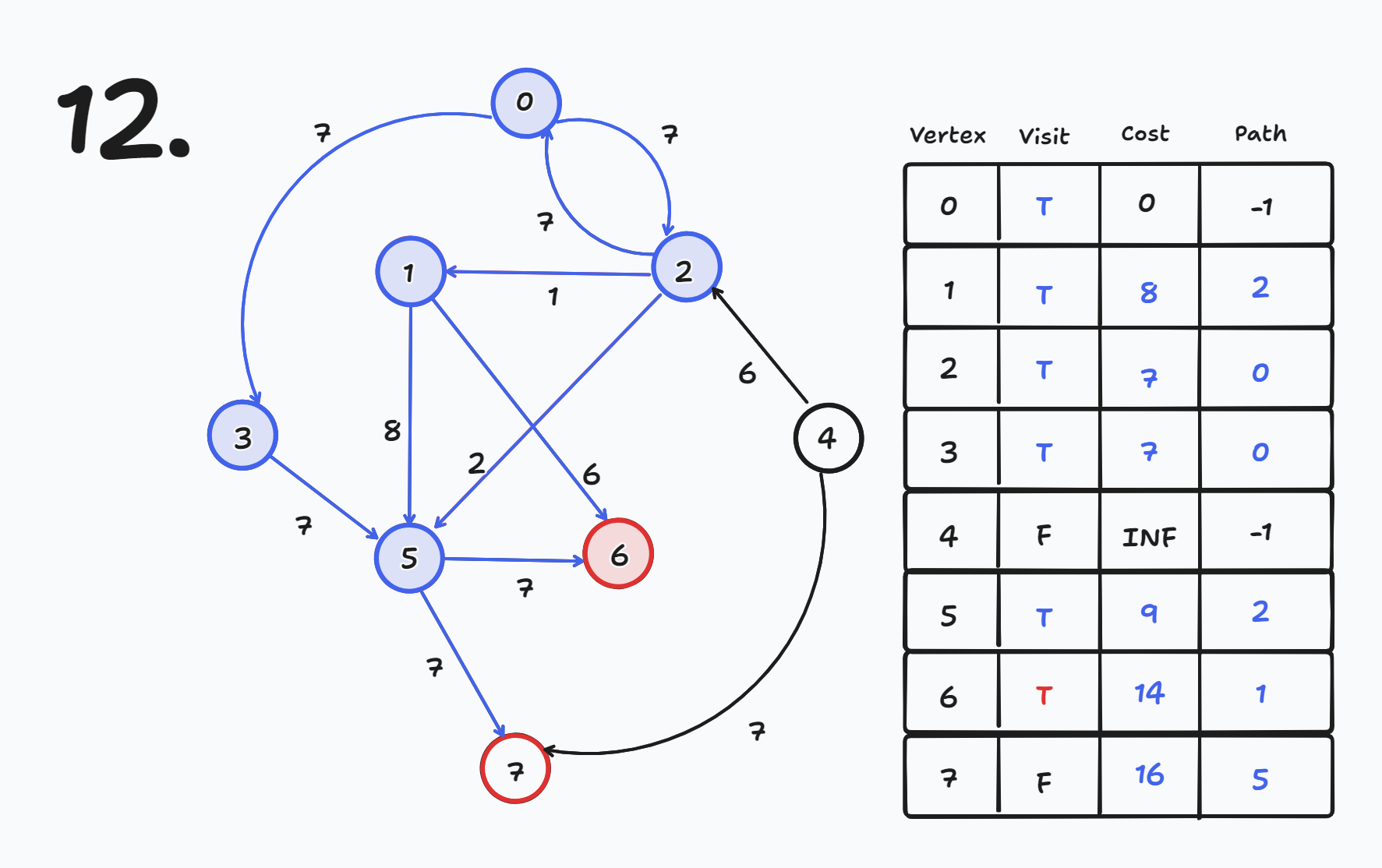
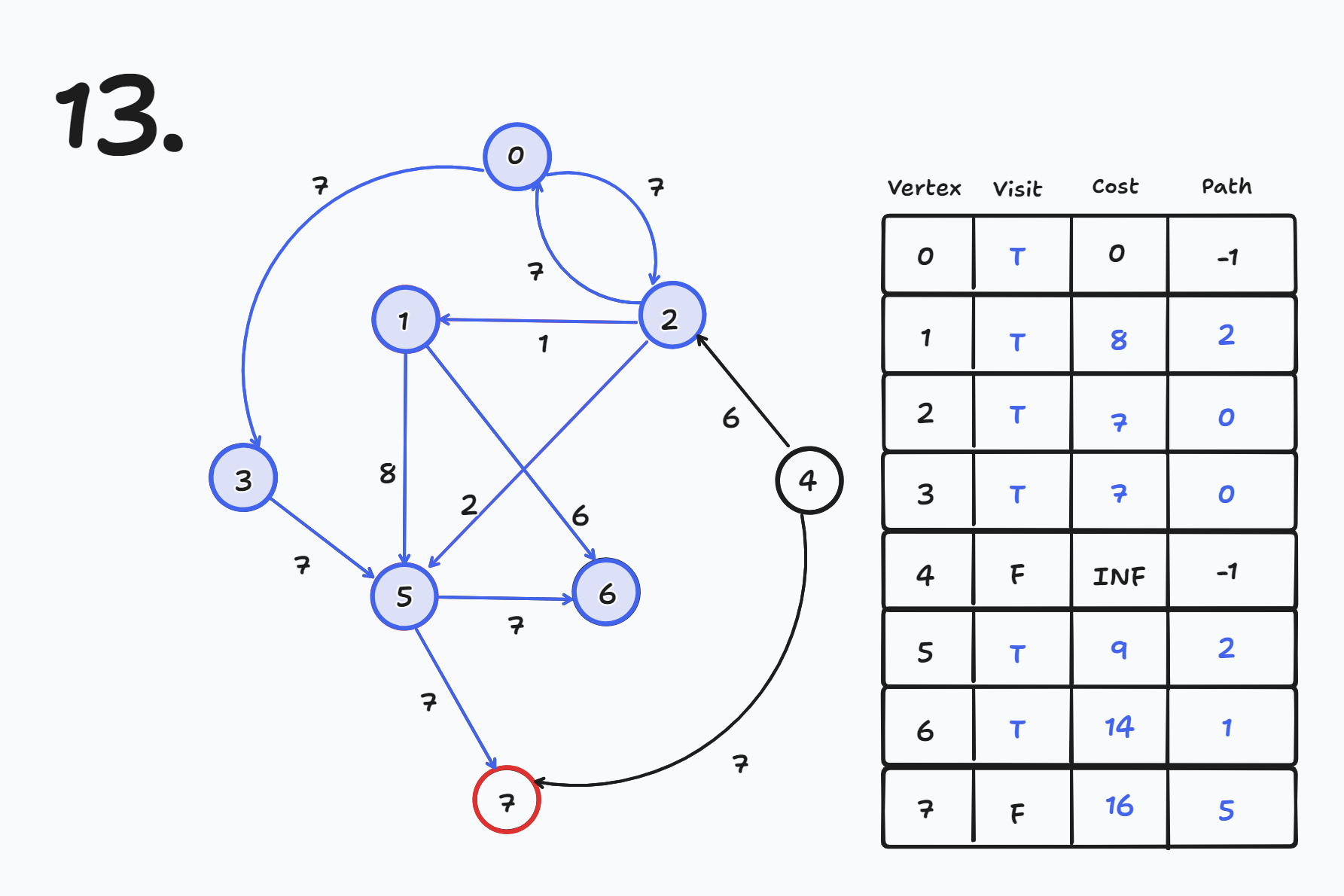
# 개요
리팩토링 8장, 데이터 체계화 읽고 간단 정리
각 카탈로그에서 설명하는 내용 중 중요하게 생각하는 부분 작성하고 내 생각도 덧붙임
코드 작성하다가 이 예시가 이거구나 싶을 때는 예시코드도 붙일 예정
# 데이터 체계화
객체지향 언어는 구형 언어의 간순 데이터 타입으론 불가능했던 것까지 할 수 있는 새로운 타입을 정의 할 수 있어서 좋다.
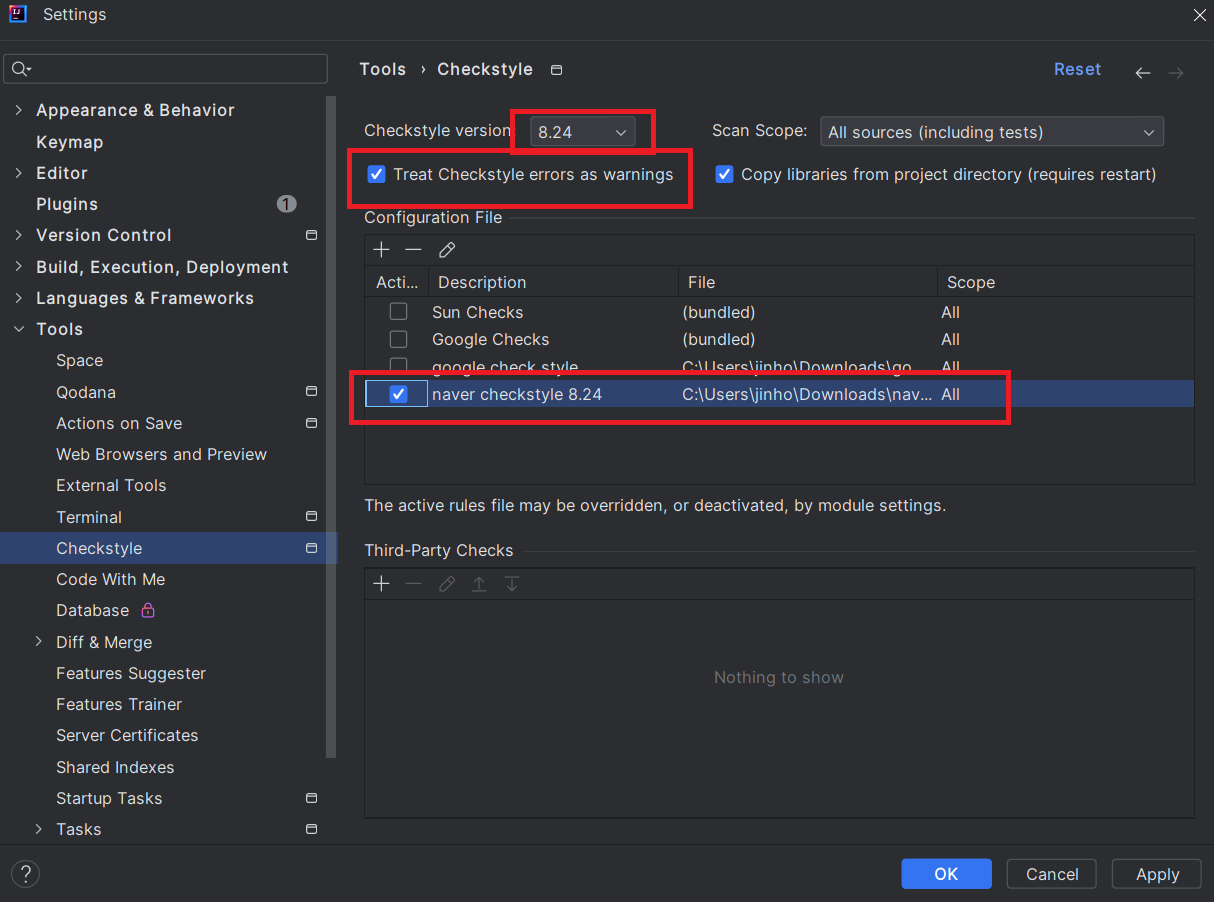
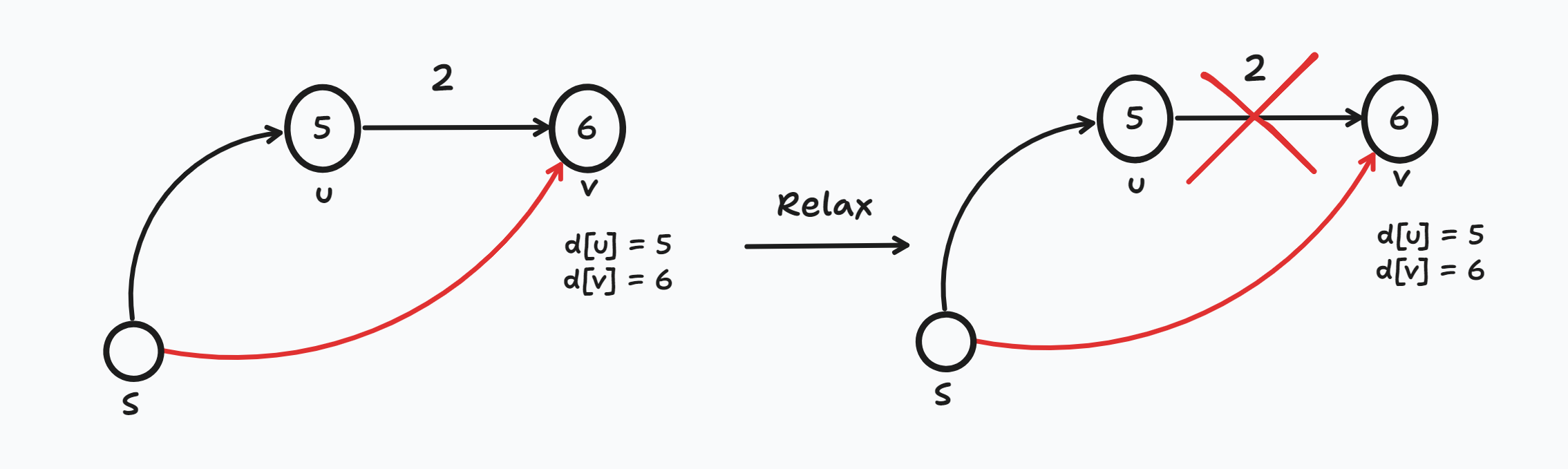
Self Encapsulate Field (필드 자체 캡슐화)
필드에 직접 접근할 때 그 필드로의 결합에 문제가 생길 때 getter/setter 메서드를 작성하여 그 메서드를 통해서 접근하게 하자
- VO, DTO등의 클래스를 만들면 습관적으로 getter/setter 메서드를 만들긴 한다. (lombok을 쓰기도)
- 근데 사실 습관적으로 getter/setter 메서드를 만드는 경향이 있다.
- 캡슐화 목적으로 필드에 직접 접근할 수 없게 private로 선언하고 메서드를 통해서 접근하도록 하기 위해서이다.
- 하지만 그게 캡슐화일까? 결국 직접 접근이 안 될 뿐이지 메서드로 접근할 수 있는데 그게 정보보호/은닉의 효과가 있다고 생각은 하지 않는다. 확실하게 아는 것이 아니기 때문에 더 공부해야 할 것 같다.
변수 간접 접근 방식은 하위 클래스가 메서드에 해당 정보를 가져오는 방식을 재정의 할 수 있어서 데이터 관리가 더 유연해진다.
변수 직접 접근 방식은 코드를 더욱 알아보기 쉽게 한다.
- 클린코드의 관점으로 봤을 땐 더욱 알아보기 쉬운 직접 접근 방식이 더 좋은것 같다.
Replace Data Value with Object (데이터 값을 객체로 전환)
데이터 항목에 데이터나 기능을 더 추가해야 할 때는 데이터 항목을 객체로 만들자.
개발 초기 단계에는 단순 정보를 간단한 데이터 항목으로 표현하는데 개발이 진행되다 보면 그런 간단한 항목이 점점 복잡해진다.
한 두 항목은 객체 안에 메서드를 넣어도 되겠지만 금세 '중복 코드'나 '잘못된 소속'이라는 구린내가 풍기게 된다. 그렇다면 즉시 데이터 값을 객체로 전환하자.
- 주로 한 클래스의 한 메서드 내에 코드를 계속 작성하다 보면 어느 부분을 메서드로 추출해야하는 때가 생긴다.
- 그렇게 메서드 추출을 통해 메서드를 여러개 만들다 보면 어떤 변수는 모든 메서드에서 공통으로 사용되기 때문에 필드로 올려야 할 때가 생긴다.
- 또 그렇게 계속 작성하다보면 한 클래스에 여러 필드가 생기게 되고 그 필드들을 하나의 객체로 전환하여 사용하는 것이 낫다는 얘기인 것 같다.
Change Value to Reference (값을 참조로 변환)
클래스에 같은 인스턴스가 많이 들어 있어서 이것들을 하나의 객체로 바꿔야 할 땐 그 객체를 참조 객체로 전환하자
참조 객체는 고객이나 계좌 같은 것이다. 각 객체는 현실에서의 한 객체에 대응하므로 둘이 같은지 검사할 때 객체 ID를 사용한다.
값 객체는 날짜나 돈 같은 것이다. 전적으로 데이터 값을 통해서만 정의된다. 두 객체가 같은지 판단할 땐 equals과 hashCode 메서드를 재정의 해야 한다.
- 값 객체와 참조 객체가 이해는 되는데 막상 코드 짜다보면 크게 구분 없이 작성하게 되는 것 같다. 두 용어가 자주 헷갈리기도 하고..
Change Reference to Value (참조를 값으로 전환)
참조 객체가 작고 수정할 수 없고 관리하기 힘들 땐 그 참조 객체를 값 객체로 만들자
참조 객체를 사용한 작업이 복잡해지는 순간이 참조를 값으로 바꿔야 할 시점이다. 참조 객체는 어떤 식으로든 제어되어야 한다.
값 객체는 변경할 수 없어야 한다는 주요 특성이 있다. 하나에 대한 질의를 호출하면 항상 결과가 같아야 한다.
- Money라는 클래스가 있고 value가 125라고 한다면 A가 가진 Money와 B가 가진 Money 객체는 같아야 한다. 반면 Person이라는 클래스의 name이 A도 아무무고 B도 아무무라고 같은 Person은 아니다.
- 근데 이게 단적인 예로 보면 이해가 잘 되는데 막상 코드 작성할 땐 크게 생각 안하고 작성한다.. 구별하는게 큰 의미가 있는건지도 잘 모르겠다.
Replace Array with Object (배열을 객체로 전환)
배열을 구성하는 특정 원소가 별의 별 의미를 지닐 땐 그 배열을 각 원소마다 필드가 하나씩 든 객체로 전환하자.
배열은 비슷한 객체들의 컬렉션을 일정 순서로 담는 용도로만 사용해야 한다.
Duplicate Observed Data (관측 데이터 복제)
도메인 데이터는 GUI 컨트롤 안에서만 사용 가능한데, 도메인 메서드가 그 데이터에 접근해야 할 땐 그 데이터를 도메인 객체로 복사하고 양측의 데이터를 동기화 하는 관측 인터페이스 Observer를 작성하자.
비즈니스 로직과 UI가 분리되는 이유
- 비슷한 비즈니스 로직을 여러 인터페이스가 처리 해야 하는 경우라서
- 비즈시스 로직까지 처리하려면 UI가 너무 복잡해져서
- GUI와 분리된 도메인 객체가 더욱 유지보수 하기 쉬워서
- 두 부분을 서로 다른 개발자가 다루게 될 수 있어서
비즈니스 로직과 UI를 분리할 때 기능은 간단히 분리할 수 있지만 데이터는 분리하기 어려울 때가 많다. 도메인 모델에 있는 데이터와 같은 의미를 지닌 데이터를 GUI 컨트롤에 넣어야하기 때문이다.
MVC를 시작으로 사용자 인터페이스 프레임워크는 이러한 데이터를 제공하고 모든 데이터의 동기화를 유지하는 다층 시스템을 사용했다.
- MVC 패턴의 예로 비유하자면 View에서 비즈니스 로직을 처리하면 안된다는 얘기인것 같다.
- 내가 했던 프로젝트를 생각하면 데이터를 복사하진 않고 View에서 Controller의 메서드를 호출하게 하고 Controller에서 비즈니스 로직을 수행 후 결과 객체를 View로 반환했는데, 이 방법을 얘기하는게 맞는건지 잘 모르겠다..
Change Unidirectional Association to Bidirectional (클래스의 단방향 연결을 양방향으로 전환)
두 클래스가 서로의 기능을 사용해야 하는데 한 방향으로만 연결되어 있을 땐 역 포인터를 추가하고 두 클래스를 모두 업데이트 할 수 있게 접근 한정자를 수정하자
역방향 참조가 아닌 다른 경로를 찾아서 해결 할 수도 있다. 하지만 이게 불가능 할 때는 양방향 참조를 설정해야한다. 처음엔 뒤죽박죽되기 쉽지만 익숙해지면 별로 복잡하지 않다.
- MVC를 예로 생각하면 View에서 Controller를 필드로 갖고 마찬가지로 Controller에서도 View를 필드로 갖는 형태인 것 같은데, 결합도가 강해져서 별로 좋은 선택은 아닌것 같다.
- 그리고 처음엔 뒤죽박죽되기 쉽지만 익숙해지면 별로 복잡하지 않다는 얘기 자체가 뒤죽박죽 될 수 있다는 얘기인데 굳이 그런 위험을 감수해야할까?
Change Bidirectional Association to Unidirectional (클래스의 양방향 연결을 단방향으로 전환)
두 클래스가 양방향으로 연결되어 있는데 한 클래스가 다른 클래스의 기능을 더 이상 사용하지 않게 됐을 땐 불필요한 방향의 연결을 끊자
양방향 연결은 쓸모가 많지만 대가가 따른다. 양방향 연결을 유지하고 객체가 적절히 생성되고 제거되는지 확인하는 복잡함이 더해진다.
양방향 연결로 인해 두 클래스는 서로 종속된다. 한 클래스를 수정하면 다른 클래스도 변경된다. 종속성이 많으면 시스템의 결합력이 강해져서 사소한 수정에도 얘기치 못한 각종 문제가 발생한다.
- 위에서 얘기했듯이 이 이유 때문에 굳이 위험을 감수해서 양방향 연결을 하는것은 좋지 않다고 생각한다. 다른 방법으로 해결하는 것이 더 낫다고 생각한다.
Replace Magic Number with Symbolic Constant (매직 넘버를 상수로 전환)
특수 의미로 지닌 리터럴이 있을 땐 의미를 살린 이름의 상수를 작성한 후 리터럴을 상수로 교체하자
상수를 사용하면 단점이나 부작용 없이 성능이 향상되며 가독성이 엄청나게 향상된다
- 이 기법도 중요하면서도 간단하게 할 수 있는 리팩토링이라고 생각한다.
Encapsulate Collection (컬렉션 캡슐화)
메서드가 컬렉션을 반환할 땐 그 메서드가 읽기 전용 뷰를 반환하게 수정하고 추가 메서드와 삭제 메서드를 작성하자.
읽기 메서드는 컬렉션 객체 자체를 반환해서는 안된다. 컬렉션을 참조하는 부분이 반환 받은 컬렉션의 내용을 조작해도 그 컬렉션이 든 클래스는 무슨 일이 일어나는지 알 수 없기 때문이다.
이로 인해 컬렉션을 참조하는 코드에게 데이터의 구조가 지나치게 노출된다. 값이 여러 개인 속성을 읽는 읽기 메서드는 컬렉션 조작이 불가능한 형식을 반환하고 불필요하게 자세한 컬렉션 구조 정보는 감춰야 한다.
- 내가 했던 프로젝트를 예로 들면 getter가 List를 반환 할 때 그냥 List 필드 자체를 반환했는데 필드 List에 들어있는 데이터들을 새 List에 복사해서 반환하는것이 더 안전하다는 생각이 들었다.
Replace Type Code with Class(분류 부호를 클래스로 전환)
기능에 영향을 미치는 숫자형 분류 부호가 든 클래스가 있을 땐 그 숫자들을 새 클래스로 바꾸자
분류 부호 이름을 상징적인 것으로 정하면 코드가 상당히 이해하기 쉬워진다.
Replace Type Code with Subclass (분류 부호를 하위 클래스로 전환)
클래스 기능에 영향을 주는 변경 불가 분류 부호가 있을 땐 분류 부호를 하위 클래스로 만들자.
분류 부호가 클래스 기능에 영향을 미치는 현상은 조건문이 있을 때 주로 나타난다.
분류 부호의 값을 검사해서 그 값에 따라 다른 코드를 실행하는 경우이다. 이런 조건문은 재정의로 바꿔야한다.
재정의를 하기 위해서 상속 구조로 고쳐야 하는데 가장 간단한 방법이 분류 부호를 하위 클래스로 전환하는 것이다.
이 기법의 장점은 클래스 사용 부분에 있던 다형적인 기능 관련 데이터가 클래스 자체로 이동 된다는 것이다.
변형된 새 기능을 추가할 땐 하위 클래스만 하나 더 추가하면 된다. 재정의를 이용하지 않는다면 조건문을 전부 찾아서 일일이 수정 해야 한다.
Replace Type Code with State/Strategy (분류 부호를 상태/전략 패턴으로 전환)
분류 부호가 클래스의 기능에 영향을 주지만 하위 클래스로 전환할 수 없을 땐 그 분류 부호를 상태 객체로 만들자
하나의 알고리즘을 단순화 해야 할 때는 전략 패턴이 더 적절하고, 강태별 데이터를 이동하고 객체를 변화하는 상태로 생각할 때는 상태 패턴이 더 적절하다
# 내 생각
대부분은 잘 이해가 됐지만 어려웠던 부분이 몇 개 있었다.
1. 값 ↔ 참조로 전환
- 값과 참조 자체는 이해가 설명과 예시 코드를 보니 이해가 되긴 했는데, 막상 내가 코드를 작성할 때 두 개를 크게 구분 지어서 생각하지 않았던 것 같다.
2. 관측 데이터 복제
- Ovserver 패턴을 잘 모르기도 했고, MVC 패턴을 알고는 있지만 데이터를 동기화 한다기 보다는 단순히 Controller에서 View로 값을 반환하는 형태로 이해하고 있어서 내용과 조금 다른 것 같다.
3. 분류 부호 → 클래스/하위클래스/상태or패턴 전환
- 미니 프로젝트를 하며 나름대로 적용 해 보았지만 내가 완전히 이해하고 딱 딱 적용했다기 보다는 책을 보며 겨우 해낸 리팩토링이라 더 공부해야 할 것 같다. 근데 확실히 그렇게 리팩토링 해 놓으니 확장성이 좋아졌다는 느낌을 받았다.