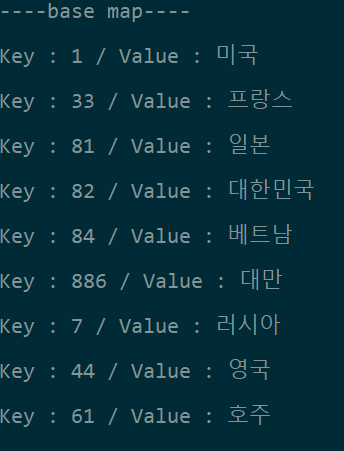
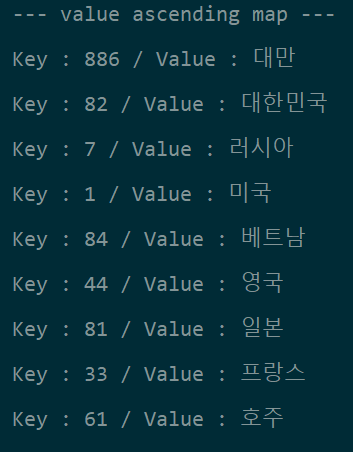
직관적으로 봐도 "나는 너를 좋아해" 와 "너는 나 좋아하니?"와 유사하고 "오늘 집에 갈거야" 와는 유사하지 않다는 걸 알 수 있다.
우리는 인간이니까 직관적으로 두 문자열이 비슷한지 전혀 다른지 판단할 수 있지만 기계는 직관적으로 판단 할 수 없다.
두 문자열의 유사도를 어떻게 판단할 수 있을까? Hamming Distance, Smith-Waterman, Sørensen–Dice coefficient 등 있지만 지금은 가장 간단한 Levenshtein Distance을 알아볼 것이다.(사실 문제 풀다가 나와서 정리하는 것)
2. 레벤슈타인 거리(Levenshtein Distance)
레벤슈타인 거리 알고리즘은 두 문자열이 같아지려면 몇번의 문자 조작(삽입, 삭제, 변경)이 필요한지 구하는 것이다.
레벤슈타인 거리 점화식
점화식만 보면 어려우니까 예시로 표현해보자.
두 문자열을 비교하면 문자 조작 비용은 총 6이다.
3. 알고리즘
위에서 말한 것 처럼 직관적으로 비용이 6인것을 알 수 있는데, 이를 알고리즘으로 어떻게 구현하는지 알아보자. LCS와 매우 유사하다.
처음 비교 대상은 공집합과 공집합이다. 둘 다 같은 문자열이기 때문에 비용은 0이다. 그 다음은 공집합과 "나" 이다. 공집합이 "나"가 되려면 비용이 1이다. 그 다음은 공집합과 "나는"이다. 마찬가지로 비용이 2가든다. 계속 진행하면 위와 같이 표가 완성된다.
이제 "너" 와 공집합 - "나" - "나는" - "나는 "... - "나는 너를 좋아해!"를 비교해보자.
"너"와 공집합을 보자. '너'가 {}이 되려면 문자를 삭제해야 한다. 그러므로 비용 1
"너"와 "나"를 보자. '너'와 '나'는 서로 다르기 때문에 교체해야 한다. 그러므로 비용 1
"너"와 "나는"을 보자. 길이가 다르기 때문에 추가해야 하고, 교체해야 한다. 그러므로 비용 2
"너"와 "나는 "을 보자. 역시 길이가 다르기 때문에 2개 추가해야 하고, 교체해야 한다. 그러므로 비용 3
"너"와 "나는 너"를 보자. 길이가 다르기 때문에 문자 3개를 추가해야 하지만, '너'는 서로 같기 때문에 그대로 둔다. 그러므로 비용 3
이런식으로 "나는 너를 좋아해!"까지 표를 완성하면 위와 같이 된다.
한번만 더 해보자. "너는"과 공집합 - "나" - "나는" - "나는 " - ... - "나는 너를 좋아해!"를 비교해보자
"너는"과 공집합을 비교해보자. "너는"이 {}이 되려면 문자 두개를 삭제해야 한다. 그러므로 비용 2
"너는"과 "나"를 비교해보자. 문자 한개 삭제와 교체가 필요하다. 그러므로 비용 2
"너는"과 "나는"을 비교해보자. '는'은 서로 같고, '너'와 '나'는 다르기 때문에 교체가 필요하다. 그러므로 비용 1
"너는"과 "나는 "을 비교해보자. 추가, 교체가 필요하다. 그러므로 비용 2
이런식으로 표를 완성하면 다음과 같이 된다.
쉽게 정리하면
글자가 서로 동일하면 대각선 값을 가져온다
변경이 필요하면 대각선 값에서 + 1을 한다.
삽입이 필요하면 위의 값에서 +1을 한다.
삭제가 필요하면 왼쪽 값에서 +1을 한다.
1~4의 경우에서 최소값을 가져온다.
4. 코드
publicclassLevenshtein{
publicstaticintgetDistance(String a, String b){
int[][] table = newint[a.length() + 1][b.length() + 1];
for (int i = 1; i <= a.length(); i++) {
table[i][0] = i;
}
for (int j = 1; j <= b.length(); j++) {
table[0][j] = j;
}
for (int i = 1; i <= a.length(); i++) {
for (int j = 1; j <= b.length(); j++) {
int insert = table[i - 1][j] + 1;
int delete = table[i][j - 1] + 1;
int replace = (a.charAt(i - 1) == b.charAt(j - 1) ? 0 : 1) + table[i - 1][j - 1];
}
}
return table[a.length()][b.length()];
}
}
package programmers.level2.압축_20210111;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
publicclassSolution{
publicint[] solution(String msg) {
Map<String, Integer> dictionary = buildBasicDictionary();
List<Integer> indexList = new ArrayList<>();
int letterIndex = 27;
int startIndex = 0;
while (startIndex < msg.length()) {
int endIndex = getEndIndex(msg, dictionary, startIndex);
String target = msg.substring(startIndex, endIndex);
indexList.add(dictionary.get(target));
if (endIndex < msg.length()) {
dictionary.put(msg.substring(startIndex, endIndex + 1), letterIndex++);
}
startIndex = endIndex;
}
return indexList.stream().mapToInt(x -> x).toArray();
}
privateintgetEndIndex(String msg, Map<String, Integer> dictionary, int startIndex){
int index;
for (index = startIndex + 1; index <= msg.length(); index++) {
if (!dictionary.containsKey(msg.substring(startIndex, index))) {
break;
}
}
return index - 1;
}
private Map<String, Integer> buildBasicDictionary(){
Map<String, Integer> map = new HashMap<>();
int index = 1;
for (char letter = 'A'; letter <= 'Z'; letter++, index++) {
map.put(letter + "", index);
}
return map;
}
}
buildBasicDictionary()에서 A~Z까지 Map에 추가한다.
while문에서 Map에 존재하는 문자열의 value를 List에 저장하고, 존재하지 않는 문자열은 Map에 저장한다.
getEndIndex()에서 endIndex를 구한다.
4. 느낀 점
처음에 getEndIndex()에서 index를 반환했다. 근데 그러면 입력 문자열의 startIndex ~ endIndex - 1까지의 subString은 Map에 존재하고, startIndex ~ endIndex까지의 subString은 존재하지 않는다. 이름이 너무 애매하고 오히려 더 헷갈려서 getEndIndex()에서 index - 1을 반환하는것으로 해결했다.
문제 자체는 카카오 문제치고는 어렵지 않은 편이다. level 2까지는 확실히 다 맞혀야 할듯
publicclassSolution{
publicint solution(int m, int n, String[] board) {
String[][] table = buildTable(m, n, board);
int count = 0;
while (true) {
int dropBlockCount = countFourBlock(m, n, table);
if (dropBlockCount == 0) {
break;
}
count += dropBlockCount;
dropTable(m, n, table);
}
return count;
}
privateString[][] buildTable(int m, int n, String[] board) {
String[][] table = newString[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
table[i][j] = board[i].charAt(j) + "";
}
}
return table;
}
privateint countFourBlock(int m, int n, String[][] table) {
boolean[][] check = newboolean[m][n];
for (int row = 0; row < m - 1; row++) {
for (int col = 0; col < n - 1; col++) {
if (table[row][col].equals(".")) {
continue;
}
checkFourBlock(table, check, row, col);
}
}
int count = 0;
for (int row = 0; row < m; row++) {
for (int col = 0; col < n; col++) {
if (check[row][col]) {
count++;
table[row][col] = ".";
}
}
}
return count;
}
privatevoid checkFourBlock(String[][] table, boolean[][] check, int currentRow,
int currentCol) {
String currentBlock = table[currentRow][currentCol];
for (int row = currentRow; row < currentRow + 2; row++) {
for (int col = currentCol; col < currentCol + 2; col++) {
if (!table[row][col].equals(currentBlock)) {
return;
}
}
}
for (int row = currentRow; row < currentRow + 2; row++) {
for (int col = currentCol; col < currentCol + 2; col++) {
check[row][col] = true;
}
}
}
privatevoid dropTable(int m, int n, String[][] table) {
for (int col = 0; col < n; col++) {
for (int row = m - 1; row >= 0; row--) {
if (table[row][col].equals(".")) {
for (int notDotRow = row - 1; notDotRow >= 0; notDotRow--) {
if (!table[notDotRow][col].equals(".")) {
table[row][col] = table[notDotRow][col];
table[notDotRow][col] = ".";
break;
}
}
}
}
}
}
}
buildTable()에서 일차원 배열의 board를 이차원 배열로 만들었다.
반복문을 돌며 countFourBlock()을 통해 지울 수 있는 block의 수를 계산 후, 전체 count에 더해주고 dropTable()을 통해 지웠다.
countFourBlock()에서 지울 수 있는 block인지 확인하는 boolean 이차원 배열을 선언 후, checkFourBlock()을 통해그림의 왼쪽 위부터 차례대로 확인했다. 마지막 행과 열은 확인 할 수 없기 때문에 반복문을 m-1, n-1까지만 돌며 확인했다. 지울 수 있는 block은 .으로 바꿔주었다.
dropTable()에서 element가 .인 칸을 찾은 후에 그 위로 .가 아닌 칸을 찾아서 두 element를 바꿔주었다.
4. 느낀 점
이차원 배열을 왼쪽 위부터 오른쪽 아래까지 차례대로 확인 👉 지울 수 있는 블록이라면 따로 마킹 👉 이차원 배열에서 마킹해놓은 개수를 덧셈 👉 블록들 삭제 👉 지울 수 있는 블록이 없을 때까지 반복
이라는 흐름은 머리로 간단히 그려졌는데, 막상 코드로 구현하려고 할 때 어려움을 느꼈다.
마킹을 어떻게 해야할까? Key, Value로 구현해야하나? 그럼 Entry를 써야하나? 이런 고민들도 있었고,
지울 수 있는 블록들은 어떻게 삭제를 해야할까? 배열에서는 delete하기 어려우니 List를 써야하나? 하는 고민도 있었다.
다른 분이 푼 코드를 보니, 그냥 따로 boolean 타입의 이차원 배열을 선언하여 해결했고
You are the "computer expert" of a local Athletic Association (C.A.A.). Many teams of runners come to compete. Each time you get a string of all race results of every team who has run. For example here is a string showing the individual results of a team of 5 runners:
"01|15|59, 1|47|6, 01|17|20, 1|32|34, 2|3|17"
Each part of the string is of the form:h|m|swhere h, m, s (h for hour, m for minutes, s for seconds) are positive or null integer (represented as strings) with one or two digits. There are no traps in this format.
To compare the results of the teams you are asked for giving three statistics;range, average and median.
Range: difference between the lowest and highest values. In {4, 6, 9, 3, 7} the lowest value is 3, and the highest is 9, so the range is 9 − 3 = 6.
Mean or Average: To calculate mean, add together all of the numbers in a set and then divide the sum by the total count of numbers.
Median: In statistics, the median is the number separating the higher half of a data sample from the lower half. The median of a finite list of numbers can be found by arranging all the observations from lowest value to highest value and picking the middle one (e.g., the median of {3, 3, 5, 9, 11} is 5) when there is an odd number of observations. If there is an even number of observations, then there is no single middle value; the median is then defined to be the mean of the two middle values (the median of {3, 5, 6, 9} is (5 + 6) / 2 = 5.5).
문제를 처음 보고 '|'의 index를 통해 시, 분, 초를 구하고 그것들을 초로 바꾸어 List에 저장해서 정렬 후, range/average/medain을 계산하려 했는데, 전에 공부했던 Time 패키지의 LocalTime을 이용하면 쉽게 해결 할 수 있겠다고 생각해서 사용해 보았다.
List<LocalTime>을 정렬하면 정렬이 안될줄 알았는데 아주 잘 되서 신기했다.
LocalTime을 이용할 때, 전에 포스팅한 Time 패키지를 참고했다. 정리 해놓길 잘했다는 생각이 든다.
여러 언론사에서 쏟아지는 뉴스, 특히 속보성 뉴스를 보면 비슷비슷한 제목의 기사가 많아 정작 필요한 기사를 찾기가 어렵다. Daum 뉴스의 개발 업무를 맡게 된 신입사원 튜브는 사용자들이 편리하게 다양한 뉴스를 찾아볼 수 있도록 문제점을 개선하는 업무를 맡게 되었다.
개발의 방향을 잡기 위해 튜브는 우선 최근 화제가 되고 있는카카오 신입 개발자 공채관련 기사를 검색해보았다.
카카오 첫 공채..'블라인드' 방식 채용
카카오, 합병 후 첫 공채.. 블라인드 전형으로 개발자 채용
카카오, 블라인드 전형으로 신입 개발자 공채
카카오 공채, 신입 개발자 코딩 능력만 본다
카카오, 신입 공채..코딩 실력만 본다
카카오코딩 능력만으로 2018 신입 개발자 뽑는다
기사의 제목을 기준으로블라인드 전형에 주목하는 기사와코딩 테스트에 주목하는 기사로 나뉘는 걸 발견했다. 튜브는 이들을 각각 묶어서 보여주면 카카오 공채 관련 기사를 찾아보는 사용자에게 유용할 듯싶었다.
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는자카드 유사도라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합A,B사이의 자카드 유사도J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합A= {1, 2, 3}, 집합B= {2, 3, 4}라고 할 때, 교집합A ∩ B= {2, 3}, 합집합A ∪ B= {1, 2, 3, 4}이 되므로, 집합A,B사이의 자카드 유사도J(A, B)= 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로J(A, B)= 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합A는 원소1을 3개 가지고 있고, 다중집합B는 원소1을 5개 가지고 있다고 하자. 이 다중집합의 교집합A ∩ B는 원소1을 min(3, 5)인 3개, 합집합A ∪ B는 원소1을 max(3, 5)인 5개 가지게 된다. 다중집합A= {1, 1, 2, 2, 3}, 다중집합B= {1, 2, 2, 4, 5}라고 하면, 교집합A ∩ B= {1, 2, 2}, 합집합A ∪ B= {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도J(A, B)= 3/7, 약 0.42가 된다.
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열FRANCE와FRENCH가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도J("FRANCE", "FRENCH")= 2/8 = 0.25가 된다.
제한 사항
입력 형식
입력으로는str1과str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어ab+가 입력으로 들어오면,ab만 다중집합의 원소로 삼고,b+는 버린다.
다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다.AB와Ab,ab는 같은 원소로 취급한다.
출력 형식
입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.
입출력 예
str1
str2
answer
FRANCE
french
16384
handshake
shake hands
65536
aa1+aa2
AAAA12
43690
E=M*C^2
e=m*c^2
65536
2. 어떻게 풀까?
두 문자열을 소문자 or 대문자로 바꿔주고, 2개의 문자열로 분할해서 배열 같은 곳에 따로 저장한다.
두 배열을 비교해서 같은 문자열이 있으면 교집합과 합집합 count를 추가해주고, 같은 문자열이 없으면 합집합 count만 추가해준다.
근데 한 배열에 중복된 문자열이 있을 수도 있으니까 배열보다 Map을 이용하는게 더 나아 보인다.
data and data1 are two strings with rainfall records of a few cities for months from January to December. The records of towns are separated by\n. The name of each town is followed by:
data and towns can be seen in "Your Test Cases:".
Task:
function:mean(town, strng)should return the average of rainfall for the citytown and the strngdata ordata1(In R and Julia this function is calledavg).
function:variance(town, strng) should return the variance of rainfall for the city town and the strngdata or data1.
제한 사항
if functions mean or variance have as parameter town a city which has no records return -1 or -1.0 (depending on the language)
Don't truncate or round: the tests will pass if abs(your\_result - test\_result) <= 1e-2 or abs((your\_result - test\_result) / test\_result) <= 1e-6 depending on the language.
mean()과 variance() 둘 다 비슷하게 구현했다. data로 주어진 strng을 \n으로 쪼개 town별로 분리하고, 분리한 town String 배열에서 :으로 쪼개 도시와 월별 rainfall로 분리했다. 그리고 rainfall끼리 전부 더해서 12로 나누어준 값을 map에 저장했다. varinace()에서는 mean()을 이용하여 variance를 구했다.
카카오톡 게임별의 하반기 신규 서비스로 다트 게임을 출시하기로 했다. 다트 게임은 다트판에 다트를 세 차례 던져 그 점수의 합계로 실력을 겨루는 게임으로, 모두가 간단히 즐길 수 있다. 갓 입사한 무지는 코딩 실력을 인정받아 게임의 핵심 부분인 점수 계산 로직을 맡게 되었다. 다트 게임의 점수 계산 로직은 아래와 같다.
다트 게임은 총 3번의 기회로 구성된다.
각 기회마다 얻을 수 있는 점수는 0점에서 10점까지이다.
점수와 함께 Single(S), Double(D), Triple(T) 영역이 존재하고 각 영역 당첨 시 점수에서 1제곱, 2제곱, 3제곱으로 계산된다.
옵션으로 스타상(*) , 아차상(#)이 존재하며 스타상(*) 당첨 시 해당 점수와 바로 전에 얻은 점수를 각 2배로 만든다. 아차상(#) 당첨 시 해당 점수는 마이너스된다.
스타상(*)은 첫 번째 기회에서도 나올 수 있다. 이 경우 첫 번째 스타상(*)의 점수만 2배가 된다. (예제 4번 참고)
스타상(*)의 효과는 다른 스타상(*)의 효과와 중첩될 수 있다. 이 경우 중첩된 스타상(*) 점수는 4배가 된다. (예제 4번 참고)
스타상(*)의 효과는 아차상(#)의 효과와 중첩될 수 있다. 이 경우 중첩된 아차상(#)의 점수는 -2배가 된다. (예제 5번 참고)
Single(S), Double(D), Triple(T)은 점수마다 하나씩 존재한다.
스타상(*), 아차상(#)은 점수마다 둘 중 하나만 존재할 수 있으며, 존재하지 않을 수도 있다.
0~10의 정수와 문자 S, D, T, *, #로 구성된 문자열이 입력될 시 총점수를 반환하는 함수를 작성하라.
제한 사항
입력 형식
점수|보너스|[옵션]으로 이루어진 문자열 3세트. 예)1S2D*3T
점수는 0에서 10 사이의 정수이다.
보너스는 S, D, T 중 하나이다.
옵선은 *이나 # 중 하나이며, 없을 수도 있다.
출력 형식
3번의 기회에서 얻은 점수 합계에 해당하는 정수값을 출력한다. 예) 37
입출력 예
예제
dartResult
answer
설명
1
1S2D*3T
37
(1^1 * 2) + (2^2 * 2) + (3^3)
2
1D2S#10S
9
(1^2) + (2^1 * -1) + (10^1)
3
1D2S0T
3
(1^2) + (2^1) + (0^3)
4
1S*2T*3S
23
(1^2 * -1 * 2) + (2^1 * 2) + (3^1)
5
1D#2S*3S
5
(1^2 * -1 * 2) + (2^1* 2) + (3^1)
6
1T2D3D#
-4
(1^3) + (2^2) + (3^2 * -1)
7
1D2S3T*
59
(1^2) + (2^1 * 2) + (3^3 * 2)
2. 어떻게 풀까?
문제에서 다트는 총 3번 던지니까 String의 split()메서드를 이용해서 점수와 보너스,옵션을 분리할 수 있을 것이다.
근데 분리할 때, empty string ("")이 생길 수 있으니 유의해야할듯.
그래서 보너스 문자에 따라 점수에 2제곱, 3제곱, *2, *-1 등을 해주어 배열에 저장하고 다 더해주면 되겠다.
문자열을 반복문 돌며 계산해줘도 될거라 생각했는데 10점이 변수가되기 때문에 그냥 분리하는게 낫겠다.
3. 코드
TDD 연습을 위해 1번 테스트 👉 실제 코드 작성 👉 리팩토링 👉 다음 테스트 👉 실제 코드 작성 👉 리팩토링 ... 순서로 계속 살을 붙여나갔다.