# 개요
벨만 포드 알고리즘 정리
용어가 좀 혼용될 수 있다
- Ex) 노드 == 정점, 간선 == 엣지
예시 그림을 다익스트라와 같은걸로 하다보니 좀 짧다 (더 좋은 예시 있으면 수정 할 예정)
# 벨만 포드 알고리즘
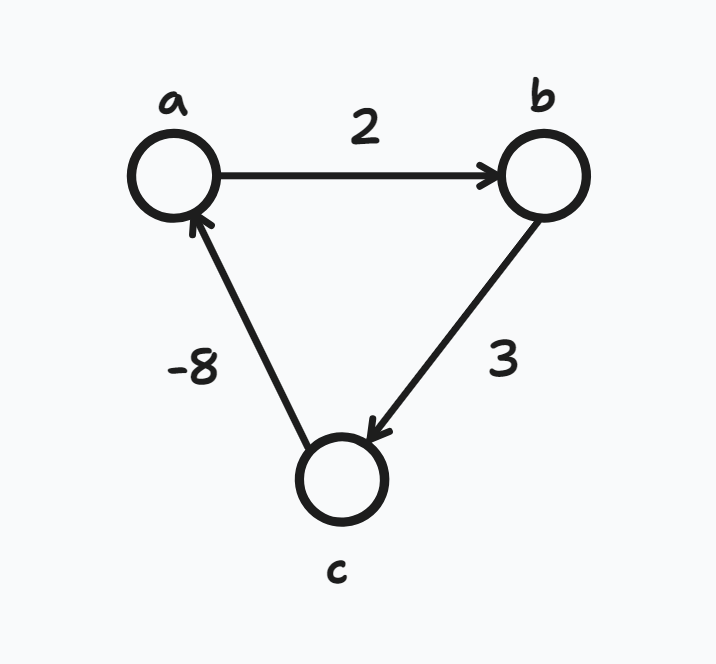
음수 사이클이 없는 그래프에서 한 정점에서 다른 모든 정점까지의 최단 경로 및 거리를 구하는 알고리즘
Dijkstra 알고리즘과의 차이
- 음수 간선이 있는 경우에도 구할 수 있다.
- Dijkstra 알고리즘 보다 느리다.
# 동작 과정
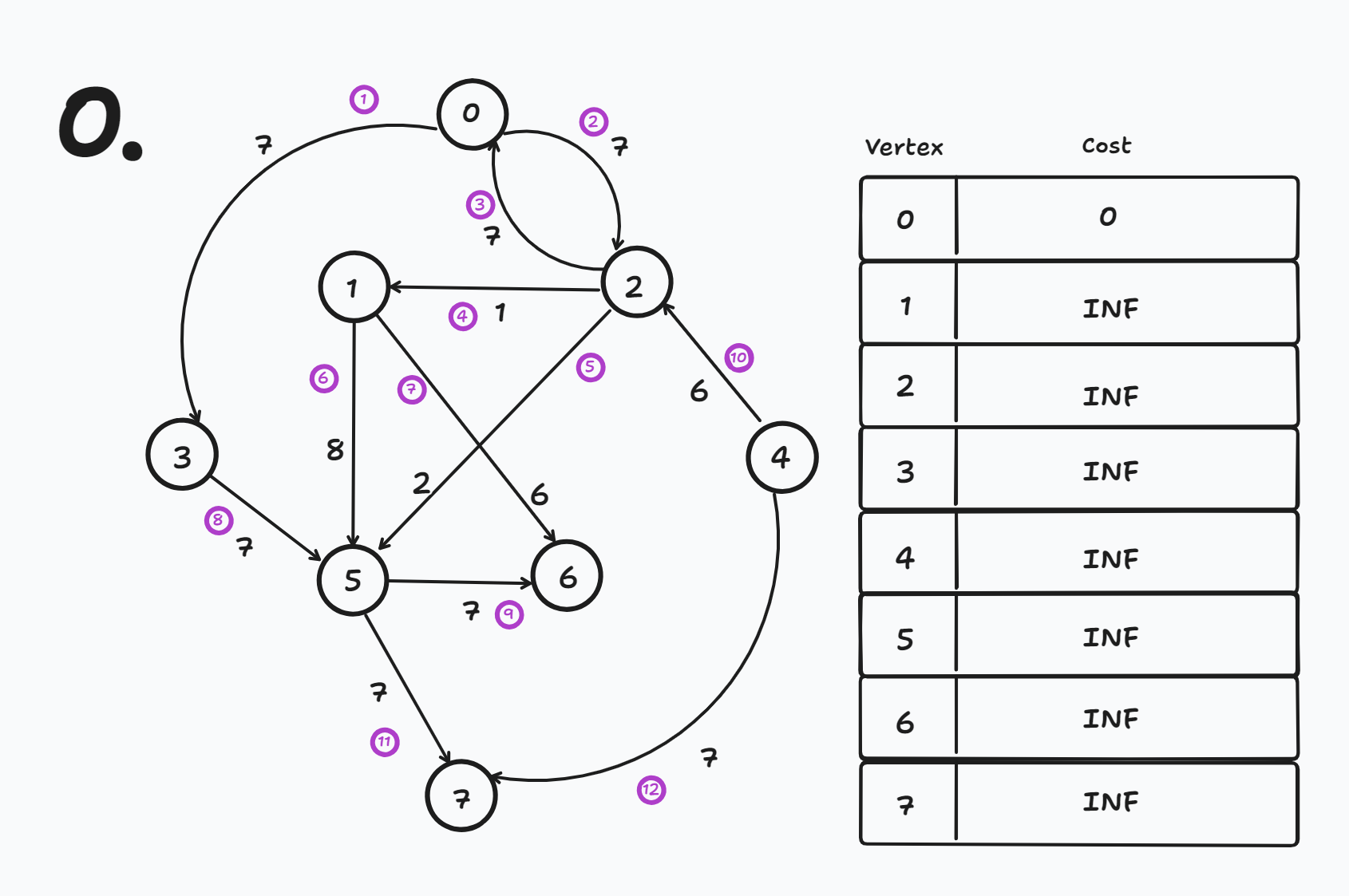
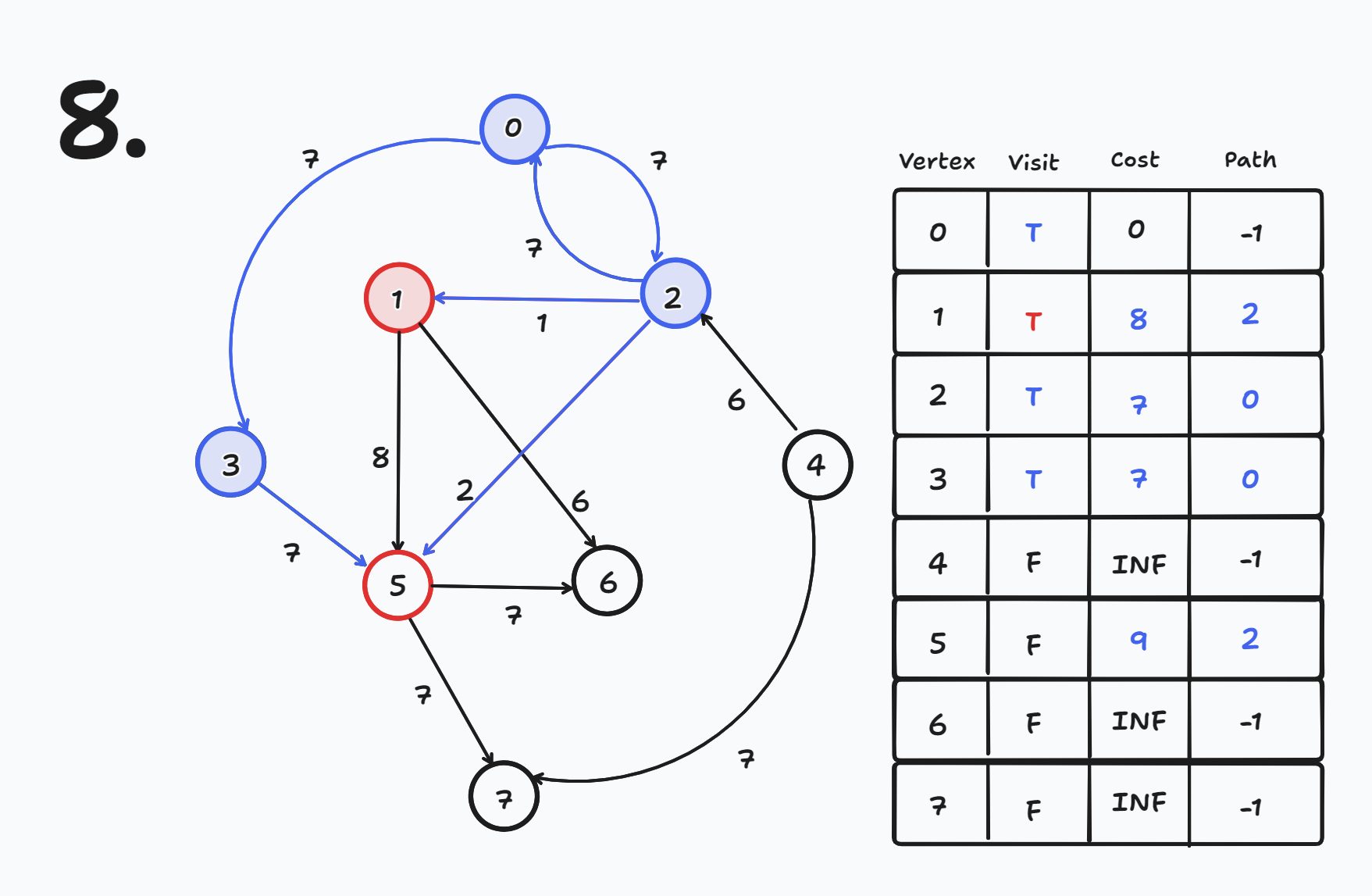
다음과 같은 순서로 간선이 그려졌다고 가정하자 (간선 순서에 따라 갱신 과정이 조금 다를 수 있다)
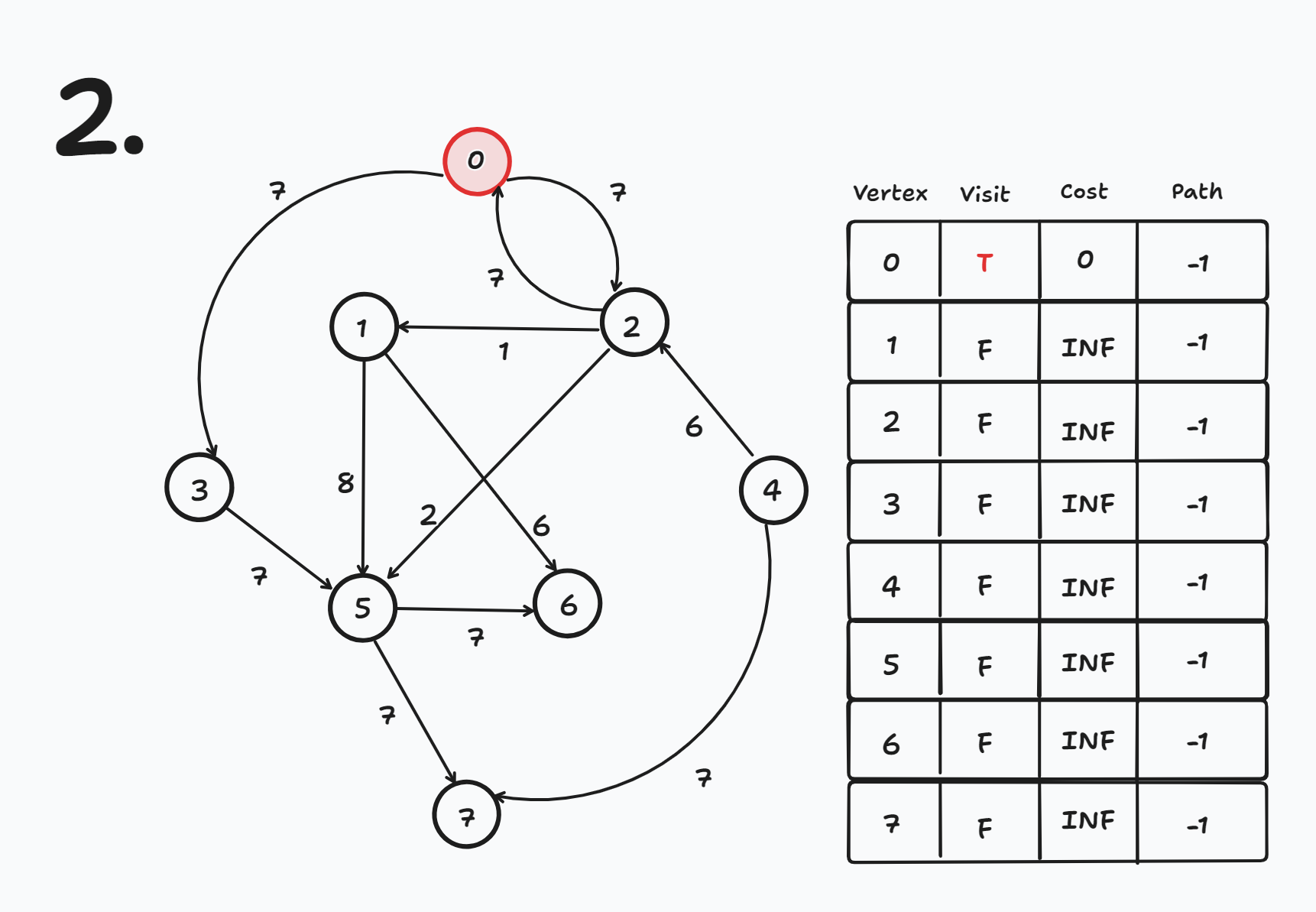
출발 노드를 0번 노드로 설정한다
- cost[0] = 0

간선 순서에 따라 Relax 연산을 수행하면
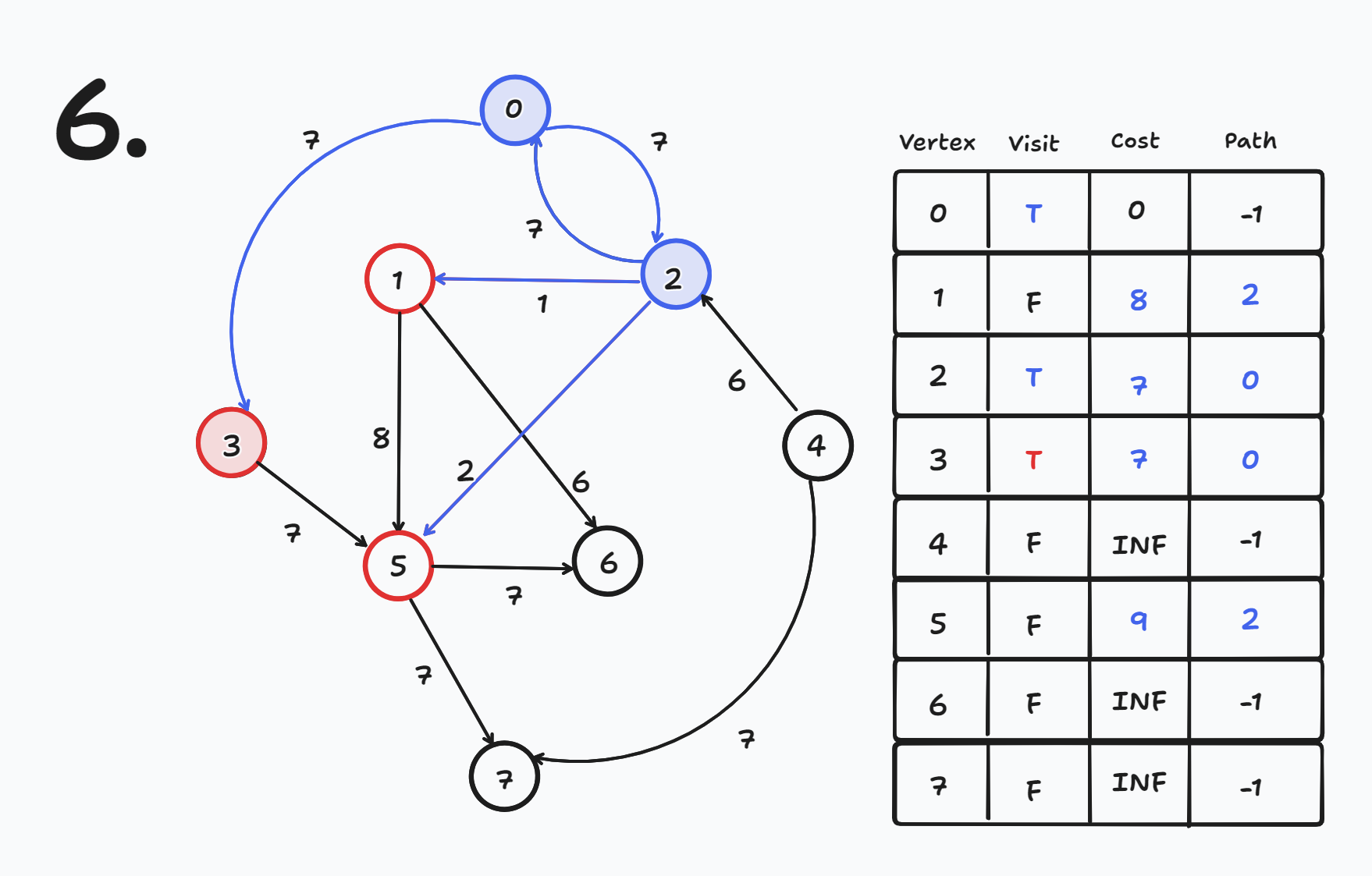
- cost[3] = INF에서 cost[0] + 7 = 7 → 7로 갱신 된다.
- cost[3] = 7
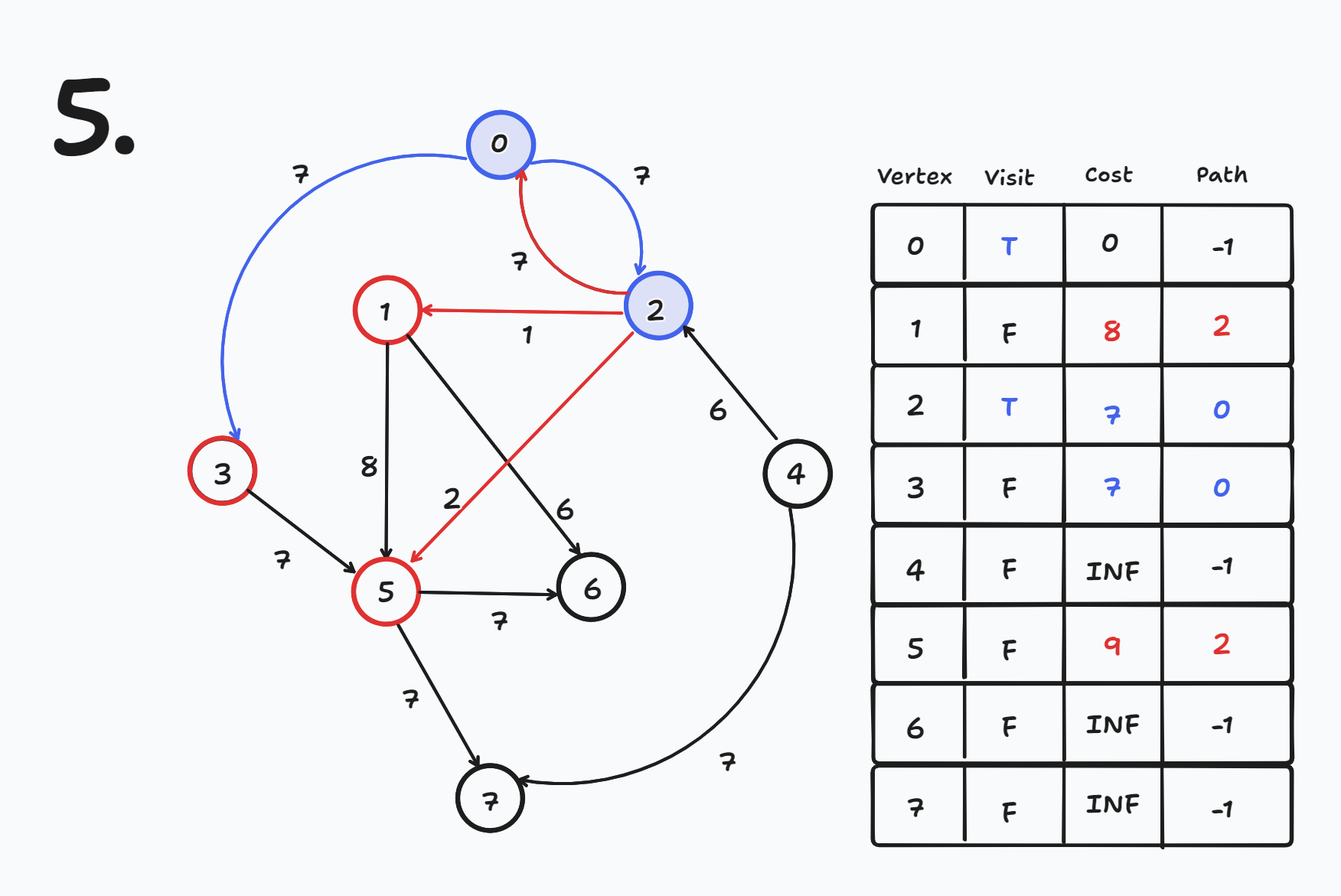
- cost[2] = INF에서 cost[0] + 7 = 7 → 7로 갱신 된다.
- cost[2] = 7
- cost[0] = 0인데 cost[2] + 7 = 14이므로 갱신 되지 않는다.
- cost[1] = INF인데 cost[2] + 1 = 8 → 8로 갱신 된다.
- cost[1] = 8
- cost[5] = INF인데 cost[2] + 2 = 9 → 9로 갱신 된다.
- cost[5] = 9
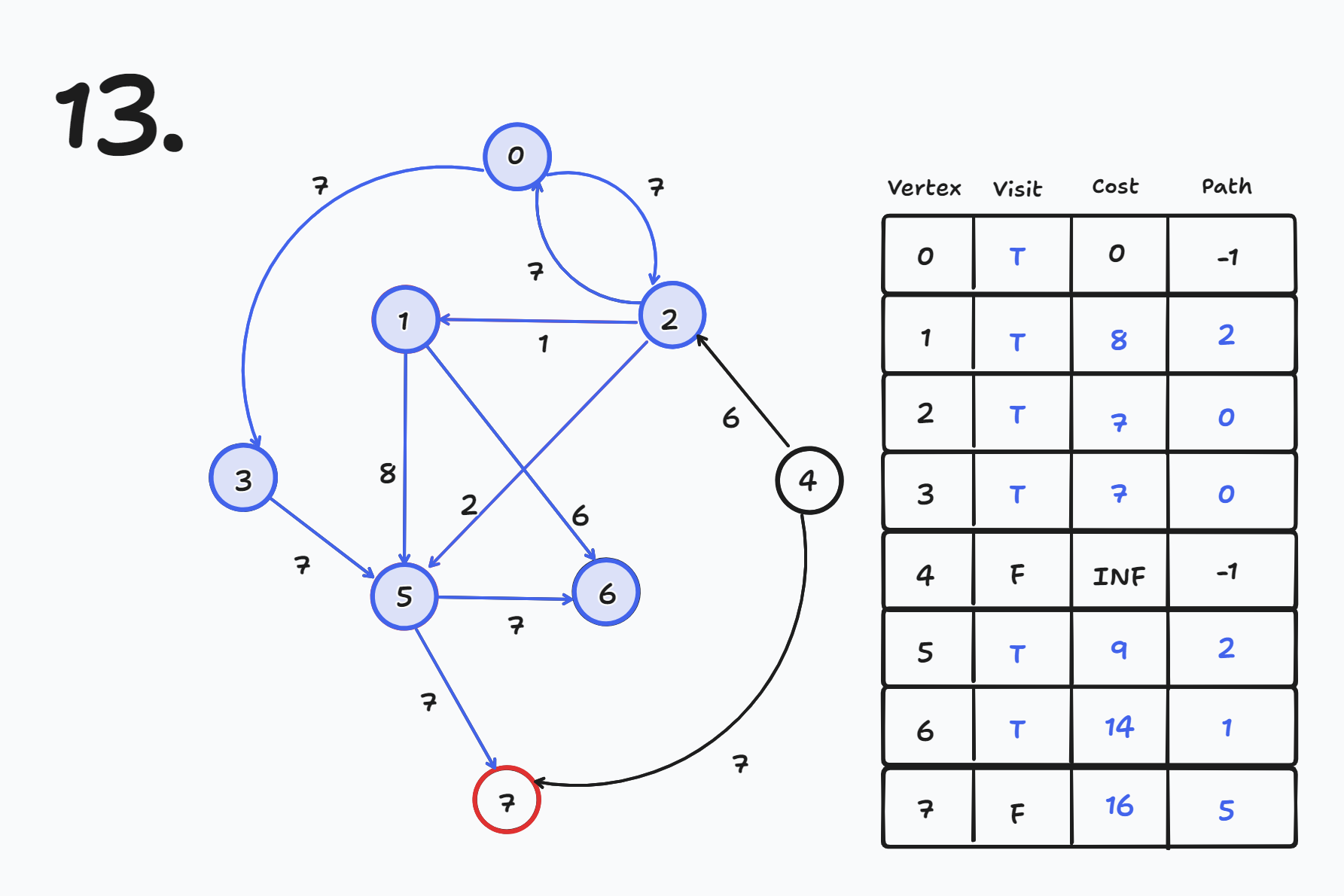
- cost[5] = 9인데 cost[1] + 8 = 16이므로 갱신 되지 않는다.
- cost[6] = INF인데 cost[1] + 6 = 14 → 14로 갱신 된다.
- cost[6] = 14
- cost[5] = 9 인데 cost[3] + 7 = 14이므로 갱신 되지 않는다.
- cost[6] = 14인데 cost[5] + 7 = 16이므로 갱신 되지 않는다.
- cost[2] = 7인데 cost[4] + 6 = INF이므로 갱신 되지 않는다.
- cost[7] = INF인데 cost[5] + 7 = 16 → 16으로 갱신 된다.
- cost[7] = 16
- cost[7] = INF인데 cost[4] + 7 = INF이므로 갱신 되지 않는다.
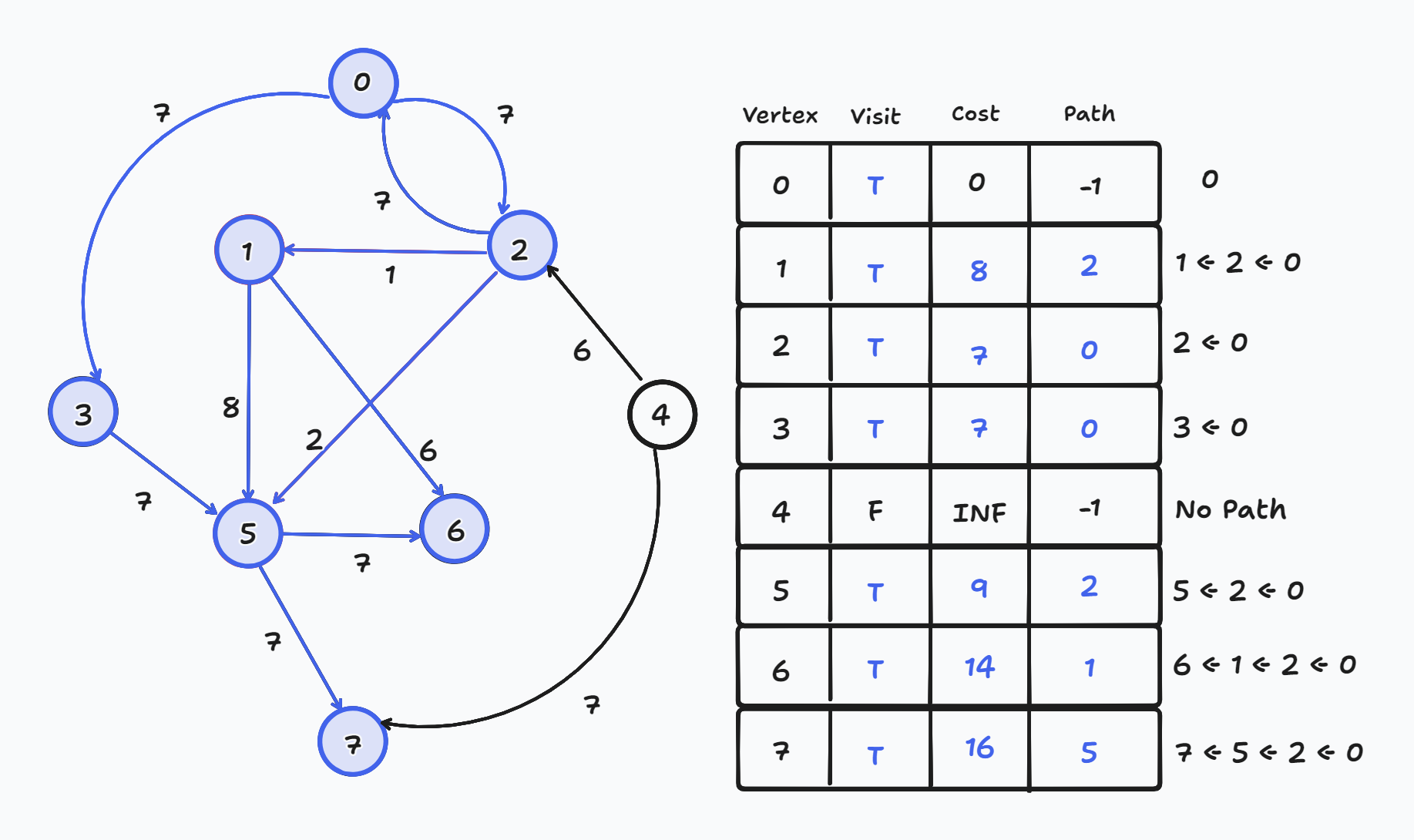
1 Round만에 모두 갱신되어 완성이 되었지만 실제로는 총 N-1번 Round를 한다.
Round가 끝나고 음수 사이클 여부를 확인하기 위해 한번의 Round를 더 수행한다.
- 그 때 다시 갱신이 된다면 음수 사이클이 존재한다는 뜻이다.
# 코드
의사코드
Bellman_Ford(G, w, S) {
Init(G, S)
for i = 1 to N-1
for each edge(u,v)
relax(u,v,w)
for each edge(u,v)
if (cost[v] > cost[u] + w(u,v))
then negative-cycle
}
자바 코드
private static int[] bellmanFord() {
int[] distance = new int[vertexCount + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
distance[source] = 0;
for (int i = 0; i < edgeCount; i++) {
for (Edge edge : edges) {
if (distance[edge.from] == Integer.MAX_VALUE) {
continue;
}
if (distance[edge.to] > distance[edge.from] + edge.weight) {
distance[edge.to] = distance[edge.from] + edge.weight;
}
}
}
for (Edge edge : edges) {
if (distance[edge.from] == Integer.MAX_VALUE) {
continue;
}
if (distance[edge.to] > distance[edge.from] + edge.weight) {
return null;
}
}
return distance;
}
# Reference
권오흠 교수님 알고리즘 유튜브 및 강의자료
Algorithm Visualization
Dynamic Programming - Bellman-Ford's Shortest Path
algorithm-visualizer.org
'Algorithm' 카테고리의 다른 글
| [Alogorithm] Dijkstra(다익스트라) 알고리즘 (1) | 2024.01.24 |
|---|---|
| [Algorithm] 최단 경로 문제 (Shortest Path Problem) (1) | 2024.01.24 |
| [Algorithm] Prim(프림) 알고리즘 (0) | 2022.01.16 |
| [Algorithm] Krsukal (크루스칼) 알고리즘 (0) | 2022.01.16 |
| [Algorithm] MST (Minimum Spanning Tree, 최소 신장 트리) (0) | 2022.01.16 |